




- -
- 100%
- +
Aus diesem Grund ist es in empirischen Studien heute üblich, Hypothesen nicht direkt zu überprüfen, sondern stattdessen NullhypothesenNullhypothese (H0) zu testen. Die Nullhypothese ist das logische Gegenteil zu meiner eigenen Hypothese, der sog. Alternativhypothese H1. Schauen wir uns ein sprachgeschichtliches Beispiel dazu an. Das Adverb bisschen geht auf das Substantiv Bissen zurück, wie in ein Bissen Brot. Es hat sich von einem Wort mit sehr konkreter Bedeutung zu einem Wort mit eher abstrakter, quantifizierender Bedeutung gewandelt. Heute kann ich nicht nur einen Bissen Lasagne essen oder mir im Sommer ein bisschen Eis gönnen, sondern auch ein bisschen müde sein oder ein bisschen spazieren gehen. Wenn es stimmt, dass bisschen graduell eine immer abstraktere Bedeutung angenommen hat, dann ist zu erwarten, dass es ursprünglich zunächst mit Substantiven auftritt, die etwas sehr Konkretes bezeichnen, womöglich sogar etwas Essbares, und dass es sich erst allmählich auf Adjektive und Verben ausdehnt. In diesem Fall wäre die H1 also: bisschen tritt im Laufe der Zeit immer häufiger mit Wörtern auf, die nicht zur Wortart Substantiv gehören. Entsprechend lautet also die H0: bisschen tritt im Laufe der Zeit nicht häufiger mit Wörtern auf, die nicht zur Wortart Substantiv gehören.
Wenn nun eine empirische Studie mit Texten aus verschiedenen Zeitstufen belegt, dass bisschen in späteren Zeitstufen tatsächlich häufiger mit Adjektiven und Verben auftritt – und zwar so viel häufiger, dass es extrem unwahrscheinlich ist, dass eine solche Verteilung durch Zufall zustande kommt –, dann können wir zwar immer noch nicht völlig sicher sein, dass die Alternativhypothese zutrifft. Aber wir können mit großer Gewissheit die Nullhypothese zurückweisen – und dadurch unsere Alternativhypothese bestärkt sehen.
Das führt uns zu der Frage, was eigentlich eine wissenschaftliche HypotheseHypothese ist und welchen Kriterien sie genügen sollte. Bortz & Döring (2006: 4) definieren eine wissenschaftliche Hypothese wie folgt:
1 Eine wissenschaftliche Hypothese bezieht sich auf reale Sachverhalte, die empirisch untersuchbar sind.
2 Eine wissenschaftliche Hypothese ist eine allgemeingültige, über den Einzelfall oder ein singuläres Ereignis hinausgehende Behauptung („All-Satz“).
3 Einer wissenschaftlichen Hypothese muss zumindest implizit die Formalstruktur eines sinnvollen Konditionalsatzes („Wenn-dann-Satz“ bzw. „Je-desto-Satz“) zugrunde liegen.
4 Der Konditionalsatz muss potenziell falsifizierbar sein, d.h., es müssen Ereignisse denkbar sein, die dem Konditionalsatz widersprechen.
Welche der folgenden Annahmen können als wissenschaftliche Hypothesen gelten, welche nicht?
Bayern trinken häufig Bier.
Bayern trinken häufiger Bier als Schwaben.
Mit zunehmendem Alter steigt das Risiko, bei einem Haushaltsunfall zu sterben.
Wenn ein Kind ohne Sprache aufwächst, spricht es am Ende Vogonisch.
Eine Annahme wie Bayern trinken häufig Bier wäre nach den oben genannten Kriterien keine wissenschaftliche Hypothese, denn es wird nicht klar, was mit „häufig“ gemeint ist – deshalb ist die Aussage nicht nach klaren Kriterien falsifizierbar: „Falsifizierbarkeit setzt begriffliche Invarianz voraus“ (Bortz & Döring 2006: 5). Anders wäre es, wenn wir „häufig“ klar definieren, z.B. als „mindestens einmal am Tag eine Maß Bier“. Dann könnten wir daraus den Wenn-dann-Satz formulieren: „Wenn jemand Bayer ist, trinkt er mindestens einmal am Tag eine Maß Bier“ und könnten folgerichtig Daten von bayerischen und nicht-bayerischen Probanden erheben und vergleichen. Bayern trinken häufiger Bier als Schwaben ist eine wissenschaftliche Hypothese, denn hier haben wir ein klares Vergleichskriterium. Gleiches gilt für die dritte Hypothese, Mit zunehmendem Alter steigt das Risiko, bei einem Haushaltsunfall zu sterben. Diese Hypothese könnte man z.B. überprüfen, indem man Daten von tödlichen Haushaltsunfällen erhebt und die Altersverteilung der Todesopfer mit der Altersverteilung in der Gesamtbevölkerung vergleicht. Die vierte Hypothese ist ein schwierigerer Fall: Sie wäre potentiell falsifizierbar, allerdings müsste man dafür ein Kind ohne Sprache aufwachsen lassen. Aus offensichtlichen Gründen erachtet man ein solches Experiment heute als unethisch und überlässt es ägyptischen Pharaonen und mittelalterlichen Herrschern (vgl. Cohen 2013 für Beispiele). Ob es sich dennoch um eine wissenschaftliche Hypothese handelt, auch wenn sie nur in der Theorie falsifizierbar ist, darüber gibt es unterschiedliche Meinungen. Da man solche Fragestellungen heute prinzipiell auch ohne Versuche an echten Menschen z.B. über sog. agentenbasierte computationale Modellierung (agent-based modelling) indirekt angehen kann, spricht im Grunde nichts dagegen, die Hypothese zumindest formal als wissenschaftliche Hypothese durchgehen zu lassen – inhaltlich ist sie natürlich offensichtlich unsinnig.
Das führt uns zu der Frage, was eigentlich eine gute wissenschaftliche Hypothese ausmacht. Eine Hypothese speist sich meist aus einer Theorie, also einem Netzwerk an erklärenden Annahmen (vgl. Bartz & Döring 2006: 15). Bisweilen werden die Begriffe Theorie und Hypothese nahezu austauschbar gebraucht, allerdings ist die Unterscheidung zwischen einem übergreifenden Netzwerk an erklärenden Annahmen und einer konkreten, falsifizierbaren Einzelannahme nicht ganz unwichtig; darauf werden wir in einem Exkurs in Kap. 4.1.2 zurückkommen. Eine gute Theorie wiederum ist nach Hussy & Jain (2002: 278f.)
logisch konsistent, also in sich widerspruchsfrei;
gut überprüfbar bzw. falsifizierbar;
einfach: sie sollte mit möglichst wenigen Annahmen möglichst viel erklären;
allgemein: eine Theorie mit größerem Geltungsbereich ist einer Theorie mit geringerem Geltungsbereich vorzuziehen.
Eng mit dem Kriterium der Einfachheit verbunden ist das Prinzip, das als Occam’s razorOccam’s razor (deutsch auch manchmal: Ockhams RasiermesserOckhams RasiermesserOccam’s razor) bekannt ist und das häufig in der Formel zusammengefasst wird: Entia non sunt multiplicanda praeter necessitatem, also frei paraphrasiert: Die Zahl der Einheiten, die zur Erklärung eines Sachverhalts herangezogen werden, soll nicht ohne Not erhöht werden. Mit anderen Worten: Die einfachere Erklärung ist die bessere, wenn es nicht gute Gründe gibt, eine voraussetzungsreichere Erklärung zu wählen. Um auf das Beispiel mit dem Kreidefleck zu Beginn des Kapitels zurückzukommen: Die Hypothese, dass Einbrecher im Haus waren und nichts gestohlen, aber einen Fleck hinterlassen haben, macht eine Annahme, die zur Erklärung der Beobachtung nicht notwendig und daher nur gerechtfertigt ist, wenn sich herausstellt, dass die einfacheren Hypothesen zur Erklärung des Phänomens nicht ausreichen.
Ganz grob zusammengefasst besteht die wissenschaftliche Methode also darin, Theorien zur Erklärung beobachtbarer Phänomene zu formulieren. Als Prüfstein für die Validität einer Theorie dient die Überprüfung von Hypothesen durch Falsifikation der entsprechenden Nullhypothese. Kann die Nullhypothese nicht falsifiziert werden, muss die entsprechende Alternativhypothese (vorerst) verworfen und die Theorie entsprechend modifiziert werden.
2.2.1 Sprachvergleich und Rekonstruktion: Die komparative Methode
Als 2015 in Südafrika die Überreste einer zuvor unbekannten Menschenart, des Homo naledi, entdeckt wurden (vgl. Berger et al. 2015), war dies eine kleine wissenschaftliche Sensation, die auch auf ein breites Presseecho stieß. Für die Paläoanthropologie, die sich mit der Entwicklungsgeschichte des Menschen befasst, sind solche Funde von zentraler Bedeutung, denn um zu verstehen, wie sich unsere Spezies evolutionär entwickelt hat, ist es wichtig, möglichst viele verwandte Spezies miteinander zu vergleichen. Dies nennt man die komparative MethodeKomparative Methode (vgl. Fitch 2010: 44–46). Derlei Vergleiche können unter anderem dazu beitragen, Rückschlüsse auf den hypothetischen letzten gemeinsamen Vorfahren, den last common ancestor, von Menschen und Schimpansen zu ziehen.
Die komparative MethodeKomparative Methode in der Sprachwissenschaft verfolgt ähnliche Ziele mit ähnlichen Mitteln. Sie ermöglicht es, Sprachstufen zu rekonstruieren, aus denen uns keinerlei Zeugnisse überliefert sind. Die komparative Methode baut auf der Grundannahme auf, dass zwischen den Sprachen der Welt Verwandtschaftsverhältnisse bestehen: Sprachen, die zur gleichen SprachfamilieSprachfamilie gehören, lassen sich demnach auf eine gemeinsame ProtospracheProtosprache zurückführen. So gehören etwa das Deutsche, Englische und Niederländische zur westgermanischen Sprachfamilie, während etwa Isländisch, Norwegisch, Dänisch und Schwedisch zur nordgermanischen zählen. Aus den Gemeinsamkeiten der jeweiligen Einzelsprachen lassen sich Eigenschaften der Protosprache, also des West- bzw. Nordgermanischen, rekonstruieren. Damit ist gemeint, dass wir eine wissenschaftlich fundierte Annahme darüber treffen, wie die jeweilige Protosprache ausgesehen haben könnte (vgl. Crowley & Bowern 2010: 79).
Natürlich sind die Verwandtschaftsverhältnisse zwischen Sprachen weitaus komplexer, als dass man einfach nur für jede Sprachfamilie eine gemeinsame „Ursprache“ annehmen müsste. So gehören das West- und Nordgermanische ihrerseits zur germanischen Sprachfamilie, zusammen mit den ausgestorbenen ostgermanischen Sprachen, zu denen das Gotische gehört, das für die Rekonstruktion des Proto-Germanischen eine zentrale Rolle spielt (vgl. Lehmann 1994: 19). Die germanischen Sprachen indes gehören ebenso wie beispielsweise die romanischen und die slawischen Sprachen zur indoeuropäischen Sprachfamilie, die in der deutschsprachigen Literatur oft auch als „indogermanische“ Sprachfamilie bezeichnet wird.
Um diese Verwandtschaftsverhältnisse zu entschlüsseln, bedarf es des Sprachvergleichs. Tab. 1 stellt die Kardinalzahlen von 1 bis 10 in sieben verschiedenen Sprachen gegenüber: drei westgermanischen, drei romanischen und einer sog. isolierten Sprache, d.h. einer Sprache, die mit keiner anderen bekannten Sprache verwandt ist. Schon ein oberflächlicher Vergleich zeigt deutliche Gemeinsamkeiten zwischen den Zahlwörtern in den eng miteinander verwandten Sprachen. Ebenso fällt auf den ersten Blick ins Auge, dass das Baskische sich ganz deutlich von den anderen Sprachen unterscheidet (außer im Falle von sei ‚sechs‘).
germanisch romanisch isoliert Dt. Engl. Nl. Franz. Ital. Span. Bask. eins one één un uno uno bat zwei two twee deux due dos bi drei three drie trois tre tres hiru vier four vier quatre quattro cuatro lau fünf five vijf cinq cinque cinco bost sechs six zes six sei seis sei sieben seven zeven sept sette siete zazpi acht eight acht huit otto ocho zortzi neun nine negen neuf nove nueve bederatzi zehn ten tien dix dieci diez hamarTab. 1: Die Zahlen von 1 bis 10 in drei westgermanischen und drei romanischen Sprachen sowie einer sog. isolierten Sprache, dem Baskischen, das mit keiner anderen bekannten Sprache verwandt ist.
Für die Ähnlichkeiten gibt es eine einfache und plausible Erklärung: Die einander ähnlichen, aber doch deutliche Unterschiede aufweisenden Sprachen haben sich aus einer gemeinsamen Vorstufe (Protosprache) entwickelt und sind im Laufe der Zeit gleichsam auseinandergedriftet. Die Frage, welche der (heutigen) Sprachen „älter“ oder „jünger“ ist, stellt sich daher zunächst nicht. Die komparative Methode geht von der – natürlich stark idealisierenden – Annahme aus, dass Aufspaltungen zwischen Sprachen plötzlich stattfinden und dass nach der Aufspaltung der Protosprache kein Kontakt mehr zwischen den daraus resultierenden Tochtersprachen besteht (vgl. Campbell 2013: 143).
Zur Anwendung der komparativen Methode
Campbell (2013: 111–134) schlägt folgende Schritte für die Durchführung einer Rekonstruktion mit Hilfe der komparativen Methode vor (ähnlich auch Crowley & Bowern 2010: 78–94; Trask 2015: 196):
Schritt 1: Kognaten finden
Unter KognatenKognat (von lat. cognatus ‚verwandt; ähnlich/übereinstimmend‘) versteht man Formen, die auf einen gemeinsamen Ursprung zurückgehen. Am Anfang der komparativen Methode steht folgerichtig die Aufgabe, potentielle Kognaten in verwandten Sprachen ausfindig zu machen, bzw. in Sprachen, bei denen man gute Gründe hat, von einer Verwandtschaft auszugehen.
Nicht alle potentiellen Kognaten müssen automatisch auch Kognaten sein. So haben wir bereits gesehen, dass Baskisch sei ‚sechs‘ zwar formal ein hohes Maß an Ähnlichkeit zu seinen Pendants in den romanischen Sprachen aufweist. Aber weil das Baskische nicht mit den romanischen Sprachen verwandt ist, kann es nicht mit Ital. sei oder Span. seis kognat sein. Allenfalls könnte es sich um ein Lehnwort handeln – eine These, die durchaus in Erwägung gezogen wurde (vgl. Uhlenbek 1940–41). LehnwörterLehnwort gelten jedoch nicht als Kognaten (vgl. Campbell 2013: 352), da EntlehnungEntlehnung zunächst ein rein „horizontaler“ Prozess ist, wie Fig. 3 zeigt: Ein Wort wie Restaurant beispielsweise wird zu einem bestimmten Zeitpunkt t aus einer Sprache (S1) in eine andere (S2) entlehnt – hier: aus dem Französischen ins Deutsche. Daher existiert es heute in beiden Sprachen, doch es lässt sich nicht auf eine gemeinsame Proto-Sprache zurückführen. Hingegen lässt sich für dt. Gast und engl. guest, zusammen mit weiteren Kognaten wie nl. gast, norw. gjest, isl. gestur oder dän. gæst eine gemeinsame Ursprungsform annehmen, nämlich germanisch *gasti-. Der Asterisk (*) zeigt hier an, dass es sich um eine rekonstruierte Form handelt, die selbst nicht belegt ist: Es ist vielmehr jene Vorform, die angesichts der überlieferten Formen als die wahrscheinlichste angesehen wird.
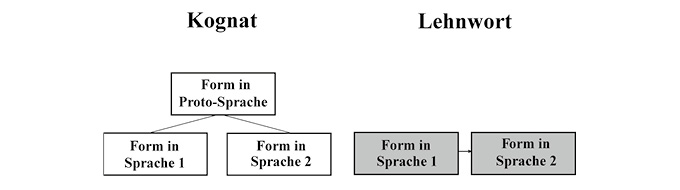
Fig. 3: Kognat vs. Lehnwort.
Schritt 2: Lautliche Entsprechungen aufzeigen
Mit Hilfe der (potentiellen) Kognaten werden anschließend systematische Lautentsprechungen herausgearbeitet. Diese müssen von solchen Entsprechungen unterschieden werden, die höchstwahrscheinlich dem Zufall geschuldet sind. So enden in Tab. 1 span. uno und cinco auf -o, die baskischen Pendants bat und bost auf -t. Hier ein Muster erkennen zu wollen, wäre indes übereilt, wie auch der Blick auf die anderen auf -o endenden spanischen Zahlwörter in der Tabelle zeigt, die keine baskische Entsprechung auf -t haben. Auch wäre eine Stichprobe von nur zwei Wörtern natürlich viel zu klein, um überzeugend eine Lautkorrespondenz aufzuzeigen.
Vergleichen wir hingegen zwei und zehn mit den Kognaten im Englischen und Niederländischen, so zeigt sich ein Muster, das wir auch in vielen anderen Wörtern wiederfinden, wie Tab. 2 verdeutlicht.
Deutsch Englisch Niederländisch Zahn tooth tand zahm tame tam (er)zählen tell (ver)tellen zehren (früher auch: ‚reißen‘, vgl. mhd. zerzern ‚zerreißen‘) tear ‚(zer)reißen‘ teren ‚zehren‘ Zinn tin tin Zuber tub tobbe Zwirn twine twijnTab. 2: Beispiele für Kognaten mit /ts/ im Deutschen und /t/ in anderen westgermanischen Sprachen.
Anhand dieser und weiterer Wörter lässt sich eine relativ klare Lautentsprechung nachweisen: Dem /ts/ im Deutschen entspricht im Englischen und Niederländischen – und auch in anderen westgermanischen Sprachen – der stimmlose Plosiv /t/. Historisch ist dies, wie wir in Kap. 4.1.1 sehen werden, auf die 2. Lautverschiebung zurückzuführen, die das Deutsche von allen anderen germanischen Sprachen trennt. Um Wandelphänomene wie die 2. Lautverschiebung entdecken zu können, bedarf es jedoch zunächst des Sprachvergleichs – genauer: der komparativen Methode.
Schritt 3: Den Proto-Laut rekonstruieren
Woher weiß man jedoch, dass bei den in Tab. 2 genannten Beispielen /ts/ der jüngere Laut ist und /t/ der ältere? Hierfür gibt es verschiedene Indizien. Erstens finden zahlreiche Lautwandelprozesse sprachübergreifend in eine bestimmte Richtung statt (Direktionalitätsprinzip): So gibt es viele Sprachen, in denen ein Wandel von /k/ zu /f/ belegt ist, während dieser Wandel in der umgekehrten Richtung praktisch nicht vorkommt (vgl. Campbell 2013: 113).
Zweitens gilt das Mehrheitsprinzip: Wenn keine anderen Indizien dagegen sprechen, wird jener Laut als Proto-Laut angenommen, der in meisten Tochtersprachen der zu rekonstruierenden Proto-Sprache auftritt (vgl. Campbell 2013: 114). So werden wir in Kap. 4.1.1 sehen, dass sich das Deutsche durch die sog. 2. Lautverschiebung von allen anderen germanischen Sprachen unterscheidet. Das zeigt sich auch in Tab. 2, denn das Englische und Niederländische haben hier wie die überwältigende Mehrheit der westgermanischen Sprachen /t/, wo das Deutsche /ts/ hat: isländisch tíu, Afrikaans tien, norwegisch und dänisch ti, schwedisch tio, färöisch tíggju – deutsch zehn. Das lässt darauf schließen, dass /t/ der ältere Laut ist.
Drittens gilt es, die gemeinsamen phonologischen Eigenschaften der unterschiedlichen Laute in den Tochtersprachen einzubeziehen. So diskutiert Campbell (2013: 116) ein Beispiel aus den romanischen Sprachen. Hier entspricht spanisch und portugiesisch /b/ im Französischen /v/ und im Italienischen /p/. Alle drei Laute teilen das Merkmal [+labial]. /b/ und /p/ teilen darüber hinaus das Merkmal [+plosiv], während /b/ und /v/ das Merkmal [+stimmhaft] gemeinsam haben. Nach dem Mehrheitsprinzip könnte man nun annehmen, dass */b/ als Proto-Laut zu rekonstruieren sei, doch spricht das Direktionalitätsprinzip dagegen, da sich stimmlose Plosive häufig zu stimmhaften Plosiven wandeln und Plosive zwischen Vokalen häufig zu Frikativen werden. Daher ist es plausibel anzunehmen, dass */p/ der gesuchte Proto-Laut ist, der in einigen der Tochtersprachen den häufig beschrittenen Wandelpfad p > b > v gegangen ist. Im Zweifelsfall kann es mithin sinnvoll sein, dem Direktionalitätsprinzip – unter Einbezug der geteilten phonologischen Merkmale der jeweiligen Laute – den Vorzug vor dem Mehrheitsprinzip zu geben.
Schritt 4: Status der Lautentsprechungen bestimmen
Bislang mag der Eindruck entstanden sein, dass einem Laut in der Protosprache immer genau ein Set an Korrespondenzen entspreche, etwa dem Proto-Laut */p/ die Korrespondenz /b/ – /p/ – /v/ im Spanischen, Portugiesischen, Französischen und Italienischen. Das ist aber keineswegs immer der Fall, wie folgendes Beispiel aus den germ. Sprachen zeigt: Das stimmhafte /d/ in Bruder und das stimmlose /t/ in Vater gehen auf den gleichen Proto-Laut zurück; die rekonstruierten ie. Formen lauten *bhrāter- bzw. *pətḗr (vgl. Pfeifer 1993). Die Formen haben sich im Deutschen durch Lautwandel auseinanderentwickelt. Synchron haben wir es daher mit zwei verschiedenen, sich jedoch teilweise überlappenden Korrespondenzenbündeln zu tun:
dt. /t/ nl. /d/ engl. /ð/ Vater vader father dt. /d/ nl. /d/ engl. /ð/ Bruder broeder brotherTab. 3: Beispiel für zwei verschiedene, einander überlappende Sets an Lautkorrespondenzen.
Die Lautkorrespondenzen in Tab. 3 ließen sich natürlich noch um weitere Sprachen ergänzen. Doch schon in dieser kleinen Auswahl an Sprachen wird deutlich, dass die Faustregel „ein Laut in Sprache A entspricht einem Laut in Sprache B“ keineswegs immer aufgeht. Bei solchen einander überlappenden Korrespondenzenbündeln muss daher in jedem Einzelfall entschieden werden, ob es sich um zwei verschiedene Korrespondenzmuster handelt oder ob sich die beiden Korrespondenzmuster auf einen Proto-Laut zurückführen lassen – was im Falle der Vater/Bruder-Kognaten sehr wahrscheinlich ist.