




- -
- 100%
- +
Schritt 5: Plausibilität des rekonstruierten Lauts überprüfen
Abschließend gilt es, die Plausibilität des rekonstruierten Lauts im Kontext des gesamten bisher rekonstruierten Phoneminventars vor dem Hintergrund typologischer Erwartungen zu überprüfen (vgl. Campbell 2013: 124–128) – in anderen Worten: zu überprüfen, wie plausibel die Annahme ist, dass a) eine Sprache das rekonstruierte Phoneminventar aufweist und dass b) in einer Sprache, die dieses Phoneminventar hat, genau dieser Laut auftaucht.
Gehen wir zunächst auf a) näher ein. In den Sprachen der Welt sind bestimmte Phoneminventare deutlich verbreiteter als andere, während einige hypothetisch denkbare Konfigurationen gar nicht auftreten. Zum Beispiel ist keine Sprache bekannt, in der es gar keine Vokale gibt. Ein rekonstruiertes Phoneminventar ganz ohne Vokale wäre folgerichtig eher unplausibel.
Weiterhin gibt es eine Reihe sprachlicher Universalien. Unter Sprachuniversalien versteht man Aussagen, die für alle (oder zumindest tendenziell für alle) Sprachen gelten. Wie „universal“ die in der Forschung angenommenen Universalien sind, ist hochumstritten, zumal nur ein Teil der auf der Welt gesprochenen Sprachen dokumentiert ist, von den bereits ausgestorbenen Sprachen ganz zu schweigen. Evans & Levinson (2009) sehen die Existenz von Sprachuniversalien daher als „Mythos“, wobei sie sich jedoch nur auf Aussagen beziehen, die ausnahmslos für alle Sprachen gelten sollen. Dass es statistische Tendenzen gibt, erkennen sie jedoch ausdrücklich an. Auf genau solche Tendenzen bezieht sich Kriterium b).
Über die komparative Methode hinaus: Weitere Möglichkeiten der Rekonstruktion
Die komparative Methode hat sich als wichtigstes Instrument der historisch-vergleichenden Sprachwissenschaft erwiesen, doch hat sie auch ihre Grenzen. So kann sie beispielsweise in isolierten Sprachen wie dem Baskischen, also solchen Sprachen, für die bisher keine Verwandten gefunden wurden, nicht angewandt werden. Hier muss man auf eine andere Methode zurückgreifen, um mögliche Vorstufen der Sprache zu rekonstruieren, nämlich die interne Rekonstruktion, die sich in manchen Fällen auch in nicht-isolierten Sprachen als Ergänzung zur komparativen Methode eignet. Ausgangspunkt der internen Rekonstruktion sind Allomorphe, also Formen, die im jeweiligen Flexionsparadigma oder auch in über Wortbildung abgeleiteten Wörtern unterschiedliche phonologische Formen haben. Im Deutschen finden wir Allomorphie z.B. in umgelauteten Formen, vgl. Maus – Mäus-e, Bub – Büb-lein. In solchen Fällen kann davon ausgegangen werden, dass die beiden Formen auf eine einzige Form zurückgehen und sich durch Lautwandel auseinanderentwickelt haben (vgl. Trask 2015: 238). Auf Grundlage dessen, was man über sprachübergreifende Lautwandeltendenzen weiß, kann man dann Lautwandelprozesse postulieren, die zur gegenwärtigen Situation geführt haben. Auch hier gilt es dann, die postulierten Prozesse im Kontext des rekonstruierten Gesamtsystems zu überprüfen (vgl. Campbell 2013: 199).
In den vergangenen Jahren haben sich zudem immer stärker computationale Methoden der Lexikostatistik und Glottochronologie etabliert. Bei diesen quantitativen Ansätzen, die allerdings in der historischen Linguistik teilweise noch mit Skepsis betrachtet werden (vgl. z.B. Campbell 2013), handelt es sich um sog. phylogenetische MethodenBayessche phylogenetische Methoden, die sich an der Evolutionsbiologie orientieren. Dass der Begriff „phylogenetische Methoden“ häufig ausschließlich mit diesen modernen Ansätzen in Verbindung gebracht wird, ist freilich etwas irreführend, denn letztlich sind auch die „klassischen“ Methoden, die zur Rekonstruktion von Sprachfamilienstammbäumen verwendet werden, phylogenetisch (von gr. φῦλον ‚Stamm‘ und γενετικός ‚Ursprung, Quelle‘). Auch die Verknüpfung zwischen Sprachwissenschaft und Evolutionsbiologie ist nicht neu: So wurde Darwin bei der Entwicklung der Evolutionsbiologie unter anderem von den Schriften August Schleichers inspiriert, der sich als einer der ersten an der Rekonstruktion der ie. Ursprache versuchte. Umgekehrt lehnen sich viele theoretische Ansätze jüngeren Datums an die Evolutionsbiologie an (z.B. Haspelmath 1999, Croft 2000).
Die Glottochronologie geht davon aus, dass es so etwas wie ein Basisvokabular gibt, also ein Inventar an Konzepten, für das es in allen Sprachen und Kulturen Wörter gibt. Das können z.B. Verwandtschaftsbezeichnungen, Farbwörter, Naturphänomene wie Sonne und Mond oder grundlegende Erfahrungen wie leben und sterben sein (vgl. z.B. Trask 2015: 350f.). Zwei häufig verwendete Listen, die sog. Swadesh-ListenSwadesh-Listen, hat Morris Swadesh zusammengestellt, eine mit 100, eine mit 200 Wörtern. Diese Listen haben z.B. Gray & Atkinson (2003) und Bouckaert et al. (2012) verwendet, um die einzelnen Aufspaltungen des Ie. möglichst genau zu datieren und damit auch Hypothesen zum Ie. zu überprüfen. Dafür nutzten sie 2.449 Kognaten (allesamt aus der 200-Wörter-Swadesh-Liste) aus 87 Sprachen und kodierten jedes der Kognaten-Sets daraufhin, ob es in der jeweiligen Sprache vorhanden ist oder nicht (0 vs. 1). Wie das aussehen kann, zeigen beispielhaft Tab. 4 und Tab. 5 (aus Atkinson & Gray 2006: 94).
In Tab. 4 sind vier Konzepte aus den Swadesh-Listen aufgeführt, zusammen mit den entsprechenden Wörtern aus sechs ie. Sprachen (darunter aus dem ausgestorbenen Hethitischen, die als älteste belegte ie. Sprache gilt). Das Wort für ‚hier‘ z.B. ist im Englischen und Deutschen kognat: here und hier. Das frz. Wort geht hingegen nicht auf die gleiche Wurzel zurück wie das engl. und dt., aber es teilt sich eine Wurzel mit dem italienischen Wort, auch wenn diese etymologische Verwandtschaft durch Lautwandel opak (undurchsichtig) geworden ist: ici und qui/qua. Mit dem Neugriechischen und Hethitischen kommen zwei weitere Wurzeln hinzu, denn die Wörter in diesen Sprachen gehören weder zum Kognatenset 1 (hier/here) noch zum Kognatenset 2 (ici/qui/qua).
In Tab. 5 ist für jedes Swadesh-Konzept in jeder der in der Stichprobe in Tab. 4 vorhandenen Sprachen angegeben, ob das jeweilige Kognaten-Set in der Sprache vorhanden ist oder nicht. Im Falle von hier findet sich in jeder der sechs Sprachen genau eine der vier Varianten: Im Englischen und Deutschen das Kognatenset 1 (hier/here), im Frz. und Italienischen das Kognatenset 2 (ici/qui/qua), im Neugriechischen das Kognatenset 3 (edo), im Hethitischen das Kognatenset 4 (ka). So entsteht eine Matrix aus binären Werten, also aus Ja/Nein-Werten bzw. Einsen und Nullen.
Englisch here 1 sea 5 water 9 when 12 Deutsch hier 1 See 5, Meer 6 Wasser 9 wann 12 Französisch ici 2 mer 6 eau 10 quand 12 Italienisch qui 2, qua 2 mare 6 acqua 10 quando 12 Neugriechisch edo 3 thalassa 7 nero 11 pote 12 Hethitisch ka 4 aruna- 8 watar 9 kuwapi 12Tab. 4: Einige Sprachen und Swadesh-Wörter, die in den Daten von Gray & Atkinson (2003, 2005) verwendet wurden. Wörter mit der gleichen Zahl sind Kognaten.
Bedeutung (Swadesh-Konzept) hier See Wasser wenn Kognatenset 1 2 3 4 5 6 7 8 9 10 11 12 Englisch 1 0 0 0 1 0 0 1 1 0 0 1 Deutsch 1 0 0 0 1 1 0 1 1 0 0 1 Französisch 0 1 0 0 0 1 0 0 0 1 0 1 Italienisch 0 1 0 0 0 1 0 0 0 1 0 1 Neugriechisch 0 0 1 0 0 0 1 0 0 0 1 1 Hethithisch 0 0 0 1 0 0 0 1 1 0 0 1Tab. 5: Kognaten-Matrix für die vier Wörter in Tab. 4. Die Ziffern in der Zeile „Kognatenset“ geben die Zahlen wieder, mit denen in Tab. 4 die einzelnen Kognaten markiert sind.
Das Vorhandensein oder Nichtvorhandensein der jeweiligen Kognatensets wird als Grundlage für Modelle der diachronen Sprachentwicklung verwendet. Genauer gesagt, wird die lexikalische Ersetzung modelliert: Angenommen z.B., die in unserer Stichprobe häufigeren Kognatensets 1 und 2 sind älter als die selteneren Kognatensets 3 und 4, dann muss ja zu einem bestimmten Zeitpunkt das alte Wort aus Kognatenset 1 oder 2 durch ein neues Wort ersetzt worden sein. In unterschiedlichen Sprachen hat diese Ersetzung für unterschiedliche Kognatensets und für unterschiedlich viele Kognatensets stattgefunden. Mit Hilfe der binären Kodierung in 1 und 0 ist also der entscheidende Prozess für die Modellierung der Zustandswechsel: von 0 zu 1 (Hinzukommen eines Kognatensets) oder von 1 zu 0 (Verlust eines Kognatensets).
Für diese Modellierung nutzen Atkinson & Gray (2003, 2006) komplexe statistische Methoden, die hier nicht ausführlich diskutiert werden können.1 Grob gesagt modelliert der Ansatz von Atkinson und Gray auf Grundlage einer Fülle von Daten unterschiedliche Sprachenstammbäume und vergleicht die so entstandenen Modelle hinsichtlich ihrer Plausibilität. Die Ergebnisse, zu denen sie auf diese Weise gelangen, interpretieren Gray & Atkinson (2003) als Evidenz für die Hypothese, dass sich das Ie. vor etwa 10.000 Jahren im anatolischen Raum auszubreiten begann.
Diese Hypothese und auch die verwendeten Methoden wurden jedoch heftig kritisiert. So kommen Pereltsvaig & Lewis (2015: 53) zu dem Schluss:
Wherever we look, we find that the model produces multiple chains of errors, consistently failing to accord with known facts about the diversification and spread of the Indo-European languages.
Einige der gegen solche phylogenetische Methoden vorgebrachten Einwände laufen darauf hinaus, dass man auf eine Vielzahl an Daten setzt und darüber die Korrektheit der Analysen im Einzelfall vernachlässigt. So lautet eine zentrale Kritik, dass sich trotz aller Bemühungen, LehnwörterLehnwort aus den Daten auszuschließen, letztlich doch relativ viele LehnwörterLehnwort eingeschlichen haben, die somit eigentlich nicht als Kognaten gelten dürften (vgl. Pereltsvaig & Lewis 2015: 81). Einen solchen Balanceakt zwischen großen Datenmengen einerseits und sorgfältiger qualitativer Analyse der einzelnen Datenpunkte andererseits bringt freilich jede empirische Arbeit mit sich. Ein weiterer, möglicherweise schwerwiegenderer Kritikpunkt betrifft die Frage, wie repräsentativ die Swadesh-Listen tatsächlich sind, zumal Swadesh keine klaren Kriterien für die Auswahl genau dieser Wörter bzw. Konzepte formuliert hat (vgl. Pereltsvaig & Lewis 2015: 72).
Aus wissenschaftstheoretischer und wissenschaftssoziologischer Perspektive ist die neu entfachte Debatte um den Ursprung des Ie. hochspannend, da hier in methodischen Fragen Welten aufeinanderprallen, die unterschiedlicher kaum sein könnten: auf der einen Seite die Vertreter der klassischen komparativen Methode, die auf genauer, händischer Analyse durch Experten beruht; auf der anderen Seite die Vertreter quantitativer Methoden, die zwar größere Datenmengen einbeziehen können, dabei aber z.T. auch fehleranfälliger sind. Inwieweit Ungenauigkeiten auf Ebene der einzelnen Datenpunkte durch eine Vielzahl an Daten „aufgefangen“ werden können, ist eine Frage, die sich bei jeder quantitativen Studie stellt und immer wieder neu erörtert werden muss. Was die hier dargestellten phylogenetischen Methoden angeht, so bleibt abzuwarten, ob sie sich eines Tages als Teil des anerkannten Methodenrepertoires der historischen Linguistik werden durchsetzen können.

Das Deutsche gehört zu den germanischen Sprachen, die sich in nord- und westgermanische Sprachen untergliedern lassen (die ostgermanischen Sprachen, zu denen das Gotische gehörte, sind ausgestorben). Die nordgermanische Sprachfamilie bilden Isländisch, Färöisch, Norwegisch, Schwedisch und Dänisch. Das Deutsche ist eine westgermanische Sprache. Weitere westgermanische Sprachen sind Englisch, Friesisch, Niederländisch, Afrikaans, Luxemburgisch und Jiddisch. Fig. 4 gibt einen Überblick über die germanischen Sprachen und die Regionen, in denen sie gesprochen werden. Auf der Karte ist jede Sprache einer bestimmten Koordinate zugewiesen. Diese Koordinaten wurden aus dem World Atlas of Language Structures (WALS) übernommen und stehen quasi stellvertretend für das Verbreitungsgebiet der jeweiligen Sprache. Das kann relativ groß sein – Deutsch zum Beispiel wird in Deutschland, Österreich und der Schweiz gesprochen, und es gibt Sprachinseln etwa in den USA und Südamerika (vgl. z.B. Glottolog, Hammarström et al. 2017).
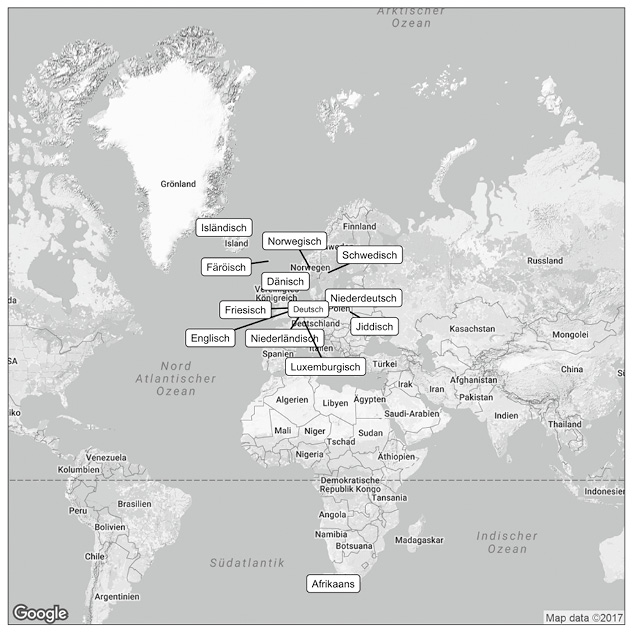
Fig. 4: Überblick über die germanischen Sprachen nach dem World Atlas of Language Structures (WALS, Dryer & Haspelmath 2013). Erstellt mit ggmap (Kahle & Wickham 2013).
Zum Weiterlesen
Eine praxisorientierte Hinführung zur Anwendung der komparativen Methode bietet Kapitel 5 von Campbell (2013). Crowley & Bowern (2010) bieten neben einem praxisorientierten Kapitel auch einen Abschnitt zur Geschichte der komparativen Methode und zu ihren Herausforderungen. Zum Einstieg eignen sich auch Kapitel 10 von Bybee (2015) sowie die Handbuchartikel von Rankin (2003) und Weiss (2015).
2.2.2 Authentische Sprachdaten: Korpuslinguistik
Was ist der Gegenstand der Sprachwissenschaft? Natürlich: Sprache. Da jeder und jede von uns eine Sprache spricht, liegt es nahe, sich in der Auseinandersetzung mit Sprache, gerade mit der eigenen Muttersprache, auf die eigene Intuition zu verlassen. Tatsächlich war diese Art, Sprachwissenschaft zu betreiben, gerade in der zweiten Hälfte des 20. Jahrhunderts weit verbreitet: Weitreichende Theorien wurden anhand selbst erdachter Beispielsätze und ad hoc gefällter Grammatikalitätsurteile erarbeitet. In einigen wenigen Bereichen ist diese Vorgehensweise noch heute verbreitet. Im Allgemeinen aber hat sich die Erkenntnis durchgesetzt, dass die eigene Intuition nicht immer ein guter Ratgeber ist (vgl. Gibbs 2006). Wer heute ernsthaft Sprachwissenschaft betreiben will, muss die eigenen Thesen auf empirische Daten stützen.
Für die historische Sprachwissenschaft war die eigene Intuition ohnehin nie eine wirkliche Option – auch wenn manche versierten Kenner des Alt- oder Mittelhochdeutschen sicherlich eine bemerkenswerte Intuition für frühere Sprachstufen entwickelt haben. Die Kenntnis dieser Sprachstufen musste immer mit Hilfe zeitgenössischer Texte erarbeitet werden. Wenn authentische Texte nach wissenschaftlichen Prinzipien ausgewogen zusammengestellt werden, um ein möglichst repräsentatives Bild einer bestimmten Sprache oder Sprachvarietät zu ermöglichen, spricht man von einem Korpus (übrigens im Neutrum: das Korpus, nicht *der Korpus!).
Ein Korpus ist also zunächst eine Sammlung authentischer Sprachdaten (vgl. Lemnitzer & Zinsmeister 2015). Diese Daten können ganz unterschiedlicher Natur sein, ebenso wie die Prinzipien, nach denen sie zusammengestellt wurden, stark variieren. Korpora des 20. und 21. Jahrhunderts umfassen oftmals nicht nur geschriebenen Text, sondern auch gesprochene Sprache oder Videoaufzeichnungen, sodass auch Informationen etwa zu sprachbegleitender Gestik oder zu Gebärdensprachen der wissenschaftlichen Untersuchung zugänglich werden. Für die Forschung zu älteren Sprachstufen sind wir hingegen ganz auf geschriebene Texte angewiesen.
Die sprachhistorischen Korpora, die für das Deutsche derzeit zur Verfügung stehen, sind gerade im Vergleich zu ihren englischen Pendants wenig umfangreich. Immerhin jedoch können wir im Vergleich zu den meisten Sprachen der Welt, die wenig bis gar nicht dokumentiert sind (vgl. z.B. Hammarström & Nordhoff 2011), auf erfreulich umfangreiche und stetig wachsende Ressourcen zurückgreifen. Eine Übersicht über derzeit verfügbare deutschsprachige Korpora findet sich in Infobox 3. Darüber hinaus ist mit „Deutsch Diachron Digital“ seit einiger Zeit eine ganze Reihe sprachhistorischer Korpora in Arbeit (http://www.deutschdiachrondigital.de/). Zur Zeit der Drucklegung dieses Buches war das Projekt jedoch noch nicht abgeschlossen.
Referenzkorpus Altdeutsch und Referenzkorpus Mittelhochdeutsch. Das Referenzkorpus Altdeutsch (REA) enthält alle überlieferten Textzeugnisse des Ahd. und Altsächischen in linguistisch aufbereiteter Form. Im Dezember 2015 wurde mit dem Referenzkorpus Mittelhochdeutsch (REM) eine weitere bedeutende Lücke in der deutschen Korpuslandschaft geschlossen. Das REM umfasst zum einen das Korpus, das der Mittelhochdeutschen Grammatik (Klein et al. 2009; weitere Bände folgen) zugrundeliegt (MiGraKo). Das MiGraKo wird ergänzt durch Zusatztexte, die unter dem etwas irreführenden Namen „Referenzkorpus Mittelhochdeutsch im engeren Sinn“ zusammengefasst sind (eReM). Wer mit einem ausgewogenen Korpus arbeiten möchte, sollte also MiGraKo nutzen, das 102 Texte mit etwa 1 Million Wortformen umfasst (vgl. Klein & Dipper 2016: 3); wer auf größere Datenmengen angewiesen ist und Abstriche bei der Ausgewogenheit machen kann, kann zusätzlich die Ergänzungstexte heranziehen.
Link: https://korpling.german.hu-berlin.de/annis3/ddd (REA)
https://www.linguistics.rub.de/annis/annis3/REM/ (REM)
Bonner Frühneuhochdeutschkorpus. Das Bonner Frühneuhochdeutschkorpus (kurz FnhdC) ist ein vergleichsweise kleines, aber dafür handannotiertes Korpus – die Probleme und Ungenauigkeiten, die mit maschineller Annotation einhergehen, finden sich hier also nicht. Es umfasst vier Zeitschnitte, die jeweils die zweite Hälfte des 14. bis 17. Jahrhunderts abdecken. Das FnhdC kann online über die Schnittstelle ANNIS durchsucht werden. Achtung: Nur ein Teil der Wörter ist lemmatisiert, also mit der Information zur Grundform des jeweiligen Wortes versehen (s.u. im Abschnitt „Anatomie eines Korpus“), daher sollte man sich nicht auf die Lemma-Annotation verlassen.
Link: https://korpora.zim.uni-due.de/Fnhd/
DWDS-Kernkorpus. Über das digitale Wörterbuch der deutschen Sprache (DWDS) sind u.a. die DWDS-Kernkorpora des 20. und des 21. Jahrhunderts sowie ein Korpus mit Texten der Wochenzeitung DIE ZEIT verfügbar. Weiterhin gibt es als Spezialkorpora z.B. ein DDR-Korpus und ein Filmuntertitelkorpus. Tipp: Die Referenz- und Zeitungskorpora lassen sich auch gemeinsam durchsuchen, indem man in der Korpusauswahl die Option „Referenz- und Zeitungskorpora (aggregiert)“ auswählt.
Link: www.dwds.de
GerManC. Das GerManC-Korpus ist so konzipiert, dass es an das Bonner Frühneuhochdeutschkorpus anknüpft, wobei der letzte Zeitschnitt des FnhdC bewusst mit dem ersten Zeitschnitt des GerManC überlappt: Wenn man beide Korpora heranzieht und in diesem Zeitschnitt deutliche Unterschiede zwischen beiden Korpora findet, kann man dann nämlich davon ausgehen, dass die beobachteten Differenzen nicht (nur) auf Sprachwandel zurückzuführen sind, sondern beispielsweise text- oder textsortenspezifisch oder gar idiosynkratisch sind. Das GerManC-Korpus umfasst etwa 600.000 Tokens aus drei Zeitschnitten von 1650 bis 1800. Das Korpus lässt sich über das Oxford Text Archive (http://ota.ox.ac.uk/desc/2544) in verschiedenen Formaten (Rohtexte und annotierte Texte) herunterladen und mit Tools wie z.B. AntConc explorieren, zudem ist es auch über Cosmas II (s.u. „Deutsches Referenzkorpus“) verfügbar.