




- -
- 100%
- +
Link: http://www.llc.manchester.ac.uk/research/projects/germanc/germancplus/
Deutsches Textarchiv. Das deutsche Textarchiv ist eine noch in Arbeit befindliche Sammlung deutschsprachiger Texte aus dem Zeitraum von 1600 bis 1900. Bei der Textauswahl wurde darauf geachtet, Texte auszuwählen, die überregional wirksam waren, um die „Entwicklung einer überregionalen Umgangssprache im hochdeutschen Sprachraum seit dem Ende der frühneuhochdeutschen Sprachperiode“ zu dokumentieren (vgl. http://deutschestextarchiv.de/doku/textauswahl). Die derzeit 2276 Texte sind vier verschiedenen Textsorten zugeordnet. Allerdings sind die Textsorten „Belletristik“ und „Gebrauchsliteratur“ derzeit noch deutlich überrepräsentiert; auch weisen die einzelnen Texte deutliche Unterschiede in ihrer Länge auf. Jedoch gibt es die Rohdaten auch zum Download, sodass sich prinzipiell aus der Textsammlung ein ausgewogenes Korpus zusammenstellen lässt.
Link: http://deutschestextarchiv.de
Deutsches Referenzkorpus (DeReKo). Das über Cosmas II zugängliche DeReKo ist in unterschiedliche sogenannte „Archive“ untergliedert, wobei aus sprachgeschichtlicher Perspektive insbesondere das HIST-Archiv interessant ist. Dieses umfasst Texte von der Mitte des 17. bis zum 20. Jahrhundert, wobei es einige Überschneidungen mit dem Hauptarchiv W gibt. Jedes Archiv besteht aus mehreren Korpora, aus denen sich bei Bedarf auch eigene, benutzerdefinierte Korpora zusammenstellen lassen.
Link: https://cosmas2.ids-mannheim.de/
Vom Korpus zur Konkordanz
Empirische Forschung beginnt immer mit einer spezifischen Fragestellung. Dabei sind der wissenschaftlichen Neugier prinzipiell keine Grenzen gesetzt: Jede Fragestellung ist grundsätzlich denkbar. Jedoch muss eine wissenschaftliche Fragestellung bestimmte Voraussetzungen erfüllen. Erstens sollte sie konkret genug sein, um anhand der vorliegenden Daten überprüft werden zu können. Zweitens sollte sie sich in eine falsifizierbare Hypothese umformulieren lassen. Eine Fragestellung wie „Essen Wissenschaftler viele Pralinen?“ ist beispielsweise sehr unspezifisch und lässt sich nur dann in eine falsifizierbare Hypothese umformulieren, wenn man sie konkreter fasst, indem man beispielsweise eine Vergleichsgruppe hinzuzieht. Die Hypothese könnte dann lauten: „Wissenschaftler essen im Durchschnitt mehr Pralinen als Romanautoren.“
Die Fragestellung bzw. die Hypothese entscheidet dann über die Wahl der Methode. Ob Wissenschaftler Pralinen essen, lässt sich mit korpuslinguistischen Methoden eher nicht klären. Die Hypothese, dass Süßwaren in wissenschaftlichen Texten häufiger erwähnt werden als in belletristischen, ließe sich hingegen durchaus mit Hilfe von Korpora überprüfen. Hierfür brauchen wir zunächst ein Korpus, das belletristische und wissenschaftliche Texte enthält. Ein solches Korpus ist das DWDS-Kernkorpus des 20. Jahrhunderts, das unter www.dwds.de verfügbar ist.
Wie jedes Korpus ist das DWDS-Kernkorpus zunächst eine Materialsammlung. Man kann es mit einer großen Bibliothek vergleichen: Ehe man sie benutzen kann, muss man sich zunächst mit ihrem Aufbau und ihrer Organisation vertraut machen sowie mit Möglichkeiten, unter den zahllosen Büchern diejenigen zu finden, nach denen man sucht. Beispielsweise wird man wenig Erfolg haben, wenn man das medizinische Nachschlagewerk „Psychrembel“ in der Bereichsbibliothek Theologie sucht. Und auch in einer medizinischen Fachbibliothek findet man es deutlich leichter, wenn man zuvor den Bibliothekskatalog zu Rate gezogen hat, als wenn man auf gut Glück drauflosstöbert.
Auf die Korpuslinguistik übertragen bedeutet dies erstens: Ich muss ein Korpus wählen, das für meine Fragestellung geeignet ist. Diesen Schritt haben wir schon getan, denn wir haben gesehen, dass das DWDS-Kernkorpus, wie es unsere Fragestellung erfordert, nach Textsorten untergliedert ist und dass sich unter diesen Textsorten auch die beiden Typen von Texten, die uns interessieren, befinden, nämlich belletristische und wissenschaftliche Texte. Dies führt uns unmittelbar zum zweiten Aspekt: Um entscheiden zu können, ob ein Korpus für unsere Fragestellung geeignet ist, müssen wir uns mit seinem Aufbau und seiner Organisation vertraut machen. Zu jedem guten Korpus gibt es eine Dokumentation, der wir beispielsweise entnehmen können, nach welchen Prinzipien das Korpus zusammengestellt wurde, welche Textsorten vertreten sind, wie groß die Subkorpora für jede Textsorte oder jeden Zeitschnitt sind, und vieles mehr.
Drittens schließlich muss man wissen, wie man ein Korpus durchsucht. Ebenso wie es im Falle der Bibliothek unerlässlich ist, sich in die Nutzung des (heutzutage meist digitalen) Bibliothekskatalogs einzuarbeiten, ist es in der Korpuslinguistik vonnöten, das jeweilige Abfragesystem kennenzulernen. Es gibt eine ganze Reihe von Abfragesystemen, deren Abfragesyntax sich teilweise unterscheidet. Ein Abfragesystem ist beispielsweise das Corpus Search, Management and Analysis System des Instituts für Deutsche Sprache, kurz COSMAS, das derzeit in der zweiten Generation vorliegt. Tatsächlich wird „COSMAS II“ häufig synonym mit dem Deutschen Referenzkorpus (DeReKo) verwendet, das über diese Schnittstelle zugänglich ist. Ein anderes Abfragesystem ist beispielsweise ANNIS, worüber die schon verfügbaren Texte von „Deutsch Diachron Digital“ zugänglich sind.
Auf die meisten Korpora kann man über web-basierte Schnittstellen zugreifen. Einige Korpusabfrageprogramme lassen sich jedoch auch herunterladen und lokal installieren. Zum Durchsuchen einfacher Textdateien eignet sich beispielsweise AntConc (http://www.laurenceanthony.net/software/antconc/). Dies setzt aber voraus, dass Sie die Textdateien auf Ihrem Rechner verfügbar haben. Viele Korpora gibt es jedoch aus urheberrechtlichen Gründen nicht zum Download, sie lassen sich nur online durchsuchen. Bei sprachhistorischen Korpora sind die urheberrechtlichen Hürden zum Glück oft geringer – das Bonner Frühneuhochdeutschkorpus, das GerManC-Korpus und das Deutsche Textarchiv beispielsweise lassen sich (fast) vollständig herunterladen, was in vielen Fällen flexiblere Suchen ermöglicht.
Kommen wir zu unserem Beispiel zurück, den Begriffen für Süßwaren. Um unsere Fragestellung korpuslinguistisch zu operationalisieren, müssen wir zunächst Begriffe auswählen, nach denen wir suchen wollen. Für unser Beispiel benutzen wir fünf Begriffe aus dem Wortfeld „Süßwaren“; für eine echte Recherche wäre natürlich eine umfassendere Suche notwendig, und man könnte z.B. auf ein Synonymlexikon zurückgreifen, um möglichst viele Lexeme zu finden und das Wortfeld so umfassend wie möglich abzudecken.
Die Lexeme, die wir für unser Beispiel verwenden, sind Süßwaren, Praline, Schokolade, Bonbon und Süßigkeit. Im Abfragefenster von DWDS geben wir ein:
$l=Süßwaren || $l=Praline || $l=Bonbon || $l=Schokolade || $l=Süßigkeit
Mit dem Operator $l geben wir an, dass wir nach dem Lemma unabhängig von der Flexionsform suchen, d.h. neben Bonbon auch nach Pluralformen (die Bonbons) oder Genitivformen (des Bonbons). Der horizontale Strich fungiert in fast allen Abfragesystemen als ODER-Operator; dass man ihn hier doppelt setzen muss, ist ein Spezifikum des DWDS-Abfragesystems.
Eine alternative, etwas effizientere Suchabfrage wäre die folgende, in der die Slashes (/) anzeigen, dass sie von sog. regulären Ausdrücken Gebrauch macht, denen wir in den folgenden Kapiteln noch öfter begegnen werden:
$l=/Süßwaren|Praline|Bonbon|Schokolade|Süßigkeit/
Da hier nicht die DWDS-spezifische Syntax verwendet wird, sondern „normale“ reguläre AusdrückeReguläre Ausdrücke, muss man hier den ODER-Operator nur einmal setzen.
Als Ergebnis erhalten wir eine sog. Konkordanz im Key Word in Context-Format, kurz KWiC. Wie der Name schon sagt, wird dabei der gesuchte Begriff – das Keyword – im Kontext angezeigt:
Belletristik an manchen Tagen nach Haufen verdorbener Pralinen , zuckrigem Fett . Belletristik » Vanille und Schokolade , wie du's immer mochtest Belletristik macht sie sich drei verschiedene Sorten Schokolade gleichzeitig : Belletristik und legten uns in die Badewanne , aßen Pralinen von Aldi , tranken Bananenmilch vom Pennymarkt Belletristik Elke läßt eine Praline in den Kaffee sinkenSolche Konkordanzen kann man in einem Tabellenkalkulationsprogramm wie Excel oder dem kostenlosen Pendant Calc von LibreOffice bearbeiten; nähere Informationen hierzu finden sich in den digitalen Begleitmaterialien. Für unsere Fragestellung jedenfalls zeigt sich, dass Süßwaren in belletristischen Texten deutlich häufiger Erwähnung finden als in wissenschaftlichen (Fig. 5).
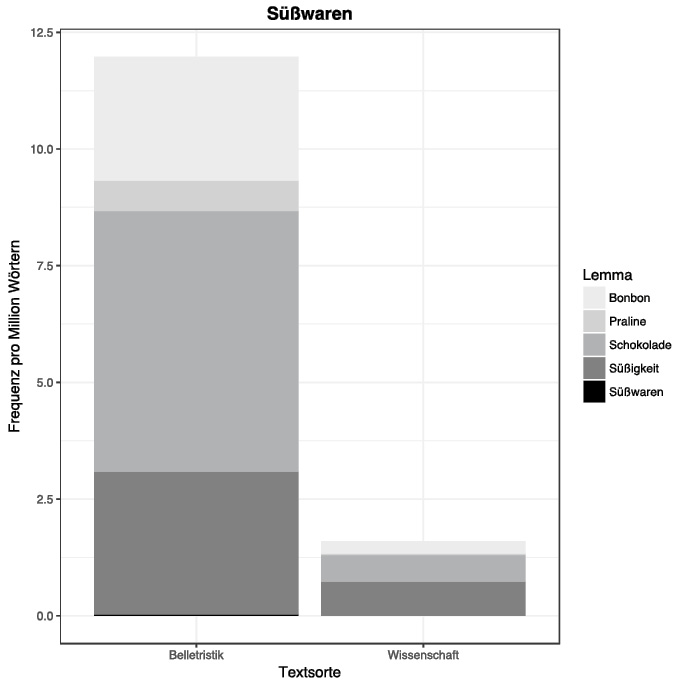
Fig. 5: Relative Frequenz von fünf Lexemen aus dem Wortfeld „Süßwaren“ in belletristischen und wissenschaftlichen Texten des DWDS-Kernkorpus des 20. Jahrhunderts.
Anatomie eines Korpus
Die Fragestellungen, die wir mit Hilfe von Korpora untersuchen wollen, gehen jedoch häufig über den einfachen Vergleich von Wortfrequenzen hinaus. Wenn wir beispielsweise syntaktische Fragestellungen untersuchen, kann es hilfreich sein, gezielt nach einzelnen Wortarten zu suchen. Aus diesem Grund sind die meisten Korpora auf Wortarten hin getaggt (Part-of-Speech-Tagging, kurz POS-Tagging). Ebenso wie die Lemmatisierung, der wir in unserem Beispiel im vorigen Abschnitt schon begegnet sind, erfolgt dieses Tagging heutzutage meist automatisch. Wenn wir beispielsweise den ersten Satz dieses Kapitels mit Hilfe des Programms TreeTagger (Schmid 1994) annotieren, erhalten wir Folgendes:
Was PWS was ist VAFIN sein der ART die Gegenstand NN Gegenstand der ART die Sprachwissenschaft NN Sprachwissenschaft ? $. ?In der linken Spalte ist der ursprüngliche Text zu sehen, der anhand der Leerzeichen in einzelne Tokens, also einzelne Wörter, untergliedert wird. Satzzeichen werden dabei ebenfalls als eigene Tokens behandelt. In der mittleren Spalte sehen wir die Part-of-Speech-Tags, rechts die Lemmata, also die unflektierten Grundformen. Neben dem Part-of-Speech-Tagging und der Lemmatisierung sind natürlich noch viele weitere Annotationen möglich. Viele Korpora sind beispielsweise auch syntaktisch geparst und lassen sich somit zum Beispiel nach Nominalphrasen, Verbalphrasen und anderen Einheiten auf syntaktischer Ebene durchsuchen. Fig. 6 zeigt dies am Beispiel der Nominalphrase der Gegenstand der Sprachwissenschaft, wobei die Knotennamen NK und AG für noun kernel (also: Kernelement einer Nominalphrase) und Attribute, Genitive (also: Genitivattribut) stehen.
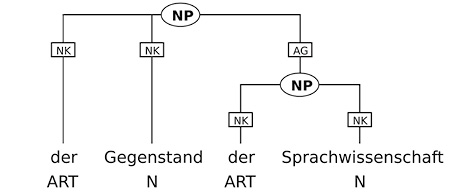
Fig. 6: Beispiel für syntaktisches Parsing.
Um die Möglichkeiten und Grenzen eines spezifischen Korpus kennenzulernen, ist es daher unerlässlich, sich zunächst in der Dokumentation zu informieren, auf welche Informationen hin es kodiert ist. Sind die einzelnen Korpusdateien öffentlich zugänglich, kann auch ein Blick auf die Rohdaten Aufschluss darüber geben, welche Möglichkeiten ein Korpus bietet.
Über das Tagging der einzelnen Tokens hinaus bieten Korpora in aller Regel auch Metainformationen zu den einzelnen Texten, beispielsweise zu Textsorte, Entstehungsjahr, Autor/in etc. Die Informationen hierzu finden sich ebenfalls in der Dokumentation.
Von der Konkordanz zur Analyse
Die Konkordanz ist natürlich nur der erste Schritt zur Analyse der Daten. Wenn wir nur Wortfrequenzen vergleichen, ist der nächste Schritt die quantitative Auswertung. In aller Regel geht der Auswertung aber noch ein weiterer Schritt voran: die Annotation. In diesem Schritt werden die Belege in der Konkordanz mit zusätzlichen Informationen versehen. Angenommen beispielsweise, wir wollen herausfinden, ob Frauenbezeichnungen in der vom Bonner Frühneuhochdeutschkorpus abgedeckten Zeitspanne eine Pejorisierung, also eine Abwertung, erfahren. Dass Frauenbezeichnungen im Deutschen dafür sehr anfällig sind, ist bekannt: So bezog sich vrouwe im Mittelhochdeutschen auf eine Edeldame, während wîp die unmarkierte Frauenbezeichnung war; heute hingegen ist Weib eindeutig abwertend, und Frau ist die Standardbezeichnung für Menschen weiblichen Geschlechts. Doch lässt sich diese Entwicklung in den Texten des Bonner Frühneuhochdeutschkorpus nachvollziehen?
Um dies zu überprüfen, suchen wir im Bonner Frühneuhochdeutschkorpus (FnhdC) nach Belegen, die dem Lemma Frau bzw. Weib zugeordnet sind. Weil im FnhdC aber auch Komposita wie Jungfrau dem Lemma Frau zugeordnet sind, entfernen wir diese anschließend manuell aus der Konkordanz. Daraufhin entscheiden wir für jeden Beleg anhand des Kontexts, ob der jeweilige Begriff positiv, neutral oder negativ verwendet wird. So geht aus dem Kontext recht eindeutig hervor, dass Weib in Beispiel (5) eher positiv verwendet wird, in (6) hingegen äußerst negativ, in (7) dagegen neutral.
(5) Ist das du mir den apphel gebist ich wil dir zu kone geben das schonste unde edilste weip das alle Krichenlandt hat (Johannes Rothe: Chronik, 15. Jh.) ‚Wenn du mir den Apfel gibst, will ich dir die schönste und edelste Frau geben, die es in ganz Griechenland gibt‘ (6) Schluͤßlich man wird vil narrischer als jennes alte hirnschellige Weib Acco das mit ihrer Bildnuß in dem Spiegel als mit einer Muhmen reden und conversiren wollen (Gotthard Heidegger: Mythoscopia, spätes 17. Jh.) (7) daß jederman sehen koͤnne daß kein ander Weib noch Kind darunter sey (Hiob Ludolf: Schaubühne, 17. Jh.)Bei der Annotation wird allerdings schnell klar, dass nur die wenigsten Fälle so eindeutig sind wie die drei genannten Beispiele. Umso wichtiger ist es, klare Annotationskriterien zu definieren, sich konsequent daran zu halten und sie in der Präsentation der Ergebnisse transparent zu machen. Einige Fragen, die sich im Blick auf die Daten zu Frau/Weib ergeben, sind beispielsweise:
1 Frau kommt häufig in der festen Fügung unsere Frau bzw. unsere liebe Frau vor, die sich auf die Jungfrau Maria bezieht. Werden diese mit einbezogen oder mit der Begründung, dass es sich dabei um stehende Wendungen handelt, die mit der freien Verwendung von Frau nichts zu tun haben, getilgt? Beides ist möglich, doch muss die Entscheidung transparent gemacht und begründet werden. Wenn die Belege berücksichtigt werden, stellt sich die Folgefrage, ob sie grundsätzlich als „positiv“ annotiert werden sollen oder nur dann, wenn ein positives Attribut wie lieb im unmittelbaren Kontext steht.
2 Eine ähnliche Frage stellt sich im Blick auf alle anderen Belege: Kann ein Beleg schon als „positiv“ annotiert werden, wenn über eine Frau gesagt wird, dass sie etwas Gutes, Richtiges, Lobenswertes tut – oder muss im unmittelbaren Kontext eindeutig ein positives Attribut oder Prädikat stehen, z.B. die edle Frau oder diese Frau ist höchst lobenswert? Das gleiche gilt umgekehrt natürlich für die Annotation „negativer“ Verwendungsweisen.
3 Sowohl Frau als auch Weib werden in den Belegen synonym mit ‚Ehefrau‘ verwendet. Sollen diese Belege mit einbezogen, getilgt oder gesondert behandelt werden? Erneut gilt: Alles ist möglich, solange es konsequent umgesetzt, transparent gemacht und gut begründet wird.
4 Was tun mit Belegen, in denen eine eindeutige Interpretation nicht möglich ist – etwa wenn man den Verdacht hat, dass in einem Beleg edles Weib ironisch gebraucht wird, sich aber nicht sicher ist und auch keine Möglichkeit hat, den größeren Kontext zu überprüfen? In solchen Fällen empfiehlt es sich, eine Kategorie „unklar“ einzuführen und ggf. in einer Kommentarspalte zu vermerken, worin die Unklarheit besteht.
Sobald wir Korpusbelege auf semantische Aspekte annotieren, stellen sich solche Fragen immer. Weil hier stets die Gefahr besteht, allzu subjektive Entscheidungen zu treffen, empfiehlt es sich, die Daten nach Möglichkeit von zwei Personen kodieren zu lassen und anschließend die Fälle, in denen keine Übereinstimmung besteht, zu diskutieren (intercoder reliability). Bei Seminar- oder Abschlussarbeiten ist das meist keine Option und wird daher auch in aller Regel nicht erwartet, aber für größer angelegte Studien sollte man, wenn irgend möglich, von dieser Möglichkeit Gebrauch machen. Wenn man die Ergebnisse berichtet, kann man dann angeben, wie hoch die Übereinstimmung war, in wie vielen Fällen nach einer Diskussion der strittigen Punkte Übereinstimmung erzielt wurde und in wie vielen Fällen keine Übereinstimmung erzielt werden konnte; die letztgenannten Fälle sollten in der Analyse nicht berücksichtigt werden.
Zum Weiterlesen
Scherer (2006) bietet eine gut lesbare, knappe Einführung in die Korpuslinguistik. Etwas ausführlicher ist die englischsprachige Einführung von McEnery & Wilson (2001). Lemnitzer & Zinsmeister (2015) gehen in ihrer Einführung auch auf die Geschichte der Korpuslinguistik und auf wissenschaftstheoretische Hintergründe ein. Wie man die Programmiersprache R in der quantitativen Korpuslinguistik fruchtbar einsetzen kann, zeigt Gries (2016).
Wer ernsthaft quantitative Linguistik betreiben möchte, muss sich auch mit Statistik auseinandersetzen. Eine gute deutschsprachige Einführung bietet Meindl (2011). Mit Levshina (2015) liegt eine noch recht neue, gut lesbare Einführung in Grundlagen der Statistik sowie verschiedenste quantitative Methoden vor. Gries (2013) bietet ebenfalls einen guten Einstieg, zumal seine Beispiele zumeist der Korpuslinguistik entstammen; teilweise ist das Buch allerdings etwas unübersichtlich, es gibt keinen Index und die Kapitelüberschriften sind nicht immer aussagekräftig. Das – allerdings recht anspruchsvolle – Standardwerk ist jedoch noch immer Baayen (2008).
Aufgaben
1 Im Begleitmaterial findet sich ein Spreadsheet mit Belegen zu „Weib“ und „Frau“ (weibfrau.csv). Öffnen Sie es mit Calc oder Excel. Achten Sie darauf, dass Sie in Excel unmittelbar nach dem Öffnen zunächst unter Daten > Text in Spalten angeben müssen, dass Tabs als Trennzeichen und einfache Anführungszeichen (’) als Textqualifizierer verwendet werden. In Calc sollte sich zunächst automatisch ein Fenster öffnen, das genau danach fragt. Hier können Sie auch angeben, dass die Datei in UTF-8 kodiert ist. Da Excel standardmäßig die Kodierung ASCII verwendet, kann es sein, dass einige Sonderzeichen nicht richtig angezeigt werden.Filtern Sie die Tabelle nun so, dass nur noch die Belege für die Lemmata „Weib“ und „Frau“ (ohne Komposita) angezeigt werden, und annotieren Sie diese in der ersten leeren Spalte nach der Verwendungsweise im Kontext: „positiv“ vs. „neutral“ vs. „negativ“.Überprüfen Sie, ob sich das Verhältnis zwischen positiven, negativen und neutralen Kontexten für beide Begriffe diachron verschiebt. Informationen dazu, wie Sie aus den Daten auf einfache Weise Tabellen und Grafiken generieren können, finden Sie im Tutorial „Korpuslinguistik mit Excel und Calc“ in den Begleitmaterialien.
2 Die Datei „suesswaren.csv“ im Begleitmaterial enthält die DWDS-Daten, die Fig. 5 zugrunde liegen. Öffnen Sie sie mit Excel oder Calc und erstellen Sie mit Hilfe des Tutorials „Tabellen mit Excel und Calc“ ein Histogramm ähnlich jenem in Fig. 5. Probieren Sie gerne auch weitere Visualisierungsvarianten aus!

Leider sind die meisten Konkordanzen, die man mit Hilfe der Online-Schnittstellen von Korpora wie dem Deutschen Referenzkorpus exportieren kann, für die Bearbeitung in Tabellenkalkulationsprogrammen nicht unmittelbar geeignet. Im digitalen Begleitmaterial finden sich daher einige Tutorials sowie interaktive Skripte, mit denen sich die Exportdateien in „gute“ Konkordanzen überführen lassen.
Was eine „gute“ Konkordanz ausmacht, lässt sich in drei Schlagworten zusammenfassen:
Eine Zeile = ein Beleg. Jede Zeile enthält genau einen Korpustreffer.
Eine Spalte = eine Kategorie. Jede Spalte enthält eine spezifische Sorte Daten. So gibt es eine Spalte für den linken Kontext, für das Keyword, für den rechten Kontext, ebenso je eine Spalte für Metainformationen wie Textsorte und Jahr.
Eine Zelle = eine Beobachtung. Jede Zelle gibt die Information über die Kategorie, der die Spalte zugeordnet ist, zum Beleg, der in der Zeile erfasst ist, an.
Fig. 7 zeigt ein Beispiel für eine weniger gelungene Konkordanz (die allerdings ungefähr den Exportdateien von COSMAS II entspricht). Textsorte und Jahr nehmen hier eine eigene Zeile in Anspruch, der Grundsatz „eine Zeile = ein Beleg“ wird also verletzt. Auch teilen sich Textsorte und Jahr mit der Nummerierung der Belege eine Spalte, der Grundsatz „eine Spalte = eine Kategorie“ wird also ebenfalls nicht eingehalten. Zudem ist in der zweiten Zeile von unten (leere Zeilen nicht mitgezählt) das Keyword in Spalte B aufgeführt, in allen anderen in Spalte C.
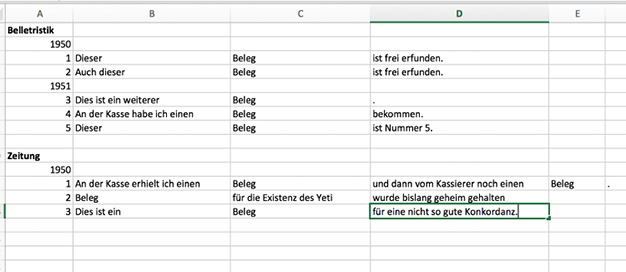
Fig. 7: Beispiel für eine für die quantitative Auswertung wenig geeignete Konkordanz.
Diese Unzulänglichkeiten sind in der Tabelle in Fig. 8 beseitigt, die den oben genannten Faustregeln folgt und die problemlos um eine weitere Spalte etwa mit semantischer Annotation erweitert werden kann.
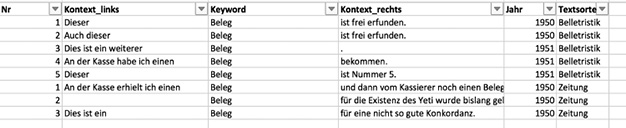
Fig. 8: Beispiel für eine gute Konkordanz nach den oben genannten Faustregeln.
COWboys im WaCkY Wide Web: Korpuslinguistik im Internet
Durch das Internet haben wir heute Zugriff auf Sprachdaten in einem Ausmaß, das vor einigen Jahrzehnten wohl noch unvorstellbar war – Kilgarriff & Grefenstette (2003: 345) bezeichnen es daher als „a fabulous linguists’ playground“. Insbesondere erlaubt uns die Nutzung von Internetquellen, konzeptionell nähesprachliche Register zu berücksichtigen und dadurch Phänomenen auf den Grund zu gehen, die in lektorierter Zeitungssprache selten bis gar nicht zu finden sind. So sind Kurzformen des Indefinitartikels wie n oder nen für ein(en) in Zeitungstexten eher selten anzutreffen. Beispielsweise untersucht Vogel (2006) das Vorkommen der „erweiterten Kurzform“ nen anstelle von n (in Kontexten wie ich hab da nen kleines Problem) auf Grundlage von Chatdaten, während Schäfer & Sayatz (2014) auf Grundlage eines mehrere Milliarden Wörter umfassenden Webkorpus unter anderem klitisierte Formen des Indefinitartikels wie auf’m oder in’n näher betrachten.