




- -
- 100%
- +
Um die Jahrtausendwende herum erschienen einige linguistische Aufsätze, die Trefferzahlen in kommerziellen Suchmaschinen wie Google als Datenquelle auswerten (vgl. Kilgarriff 2007: 147, der einige Beispiele nennt). Dieses Vorgehen ist jedoch nicht unproblematisch. Selbst wenn man nur an reinen Tokenfrequenzen interessiert ist – viel mehr ist mangels Lemmatisierung und Tagging ohnehin nicht möglich – gilt es unter anderem zu bedenken, dass die Trefferanzahlen in Google keine Tokenfrequenzen darstellen, sondern vielmehr die Anzahl an Seiten, auf denen das Gesuchte gefunden wurde. Das lässt sich an einem einfachen Beispiel illustrieren: Ein Artikel wie der, die, das oder ein Konnektor wie und wird in den allermeisten Texten sicherlich mehr als einmal anzutreffen sein. Hingegen wird man eine Formulierung wie die Terrormiliz „Islamischer Staat“ in vielen Texten nur einmal antreffen, während im weiteren Verlauf des Textes einfach mit der IS auf die islamistische Organisation Bezug genommen wird.
Ein weiteres Problem stellen Duplikate dar: Viele Texte finden sich mehrfach im Netz und werden unter Umständen bei der Google-Anfrage auch mehrfach gefunden. So ist die Wahrscheinlichkeit hoch, dass die Trefferanzahl bei einer beliebigen Suchmaschine für das Kompositum Knabenmorgen-Blütenträume zwar durchaus beträchtlich ist, die meisten Treffer allerdings Seiten sind, die entweder Goethes Gedicht „Prometheus“ enthalten oder aber aus diesem zitieren. Da die Anbieter kommerzieller Suchmaschinen ihre Algorithmen in aller Regel nicht offenlegen, steht man weiterhin vor dem Problem, dass unklar ist, wie genau eigentlich die Ergebnisse zustande kommen. So werden bei Google häufig Ergebnisse, die der Suchanfrage ähnlich sind, mitgefunden und müssten daher mühsam manuell ausgeschlossen werden. Beispielsweise fördert die Suche nach dem fiktionalen Filmcharakter Hedley Lamarr auch den Wikipedia-Eintrag zur Schauspielerin Hedy Lamarr zutage.
Das Ziel von Webkorpora ist es, das Potential, das allein schon die schiere Menge an Internettexten birgt, zu nutzen und die entsprechenden Daten linguistisch zu erschließen, ohne die Einschränkungen, die kommerzielle Suchplattformen mit sich bringen, in Kauf nehmen zu müssen. Fürs Deutsche gibt es derzeit zwei Korpora, die große Mengen an Textdaten aus dem Web in linguistisch aufbereiteter Form zugänglich machen. Das derzeit größte Webkorpus ist DECOW (Schäfer & Bildhauer 2012), derzeit (Stand Ende 2016) verfügbar in der Version DECOW16AX. Aus urheberrechtlichen Gründen enthält es jedoch keine Texte, sondern lediglich Satzsammlungen. Diese sind jedoch linguistisch annotiert, d.h. lemmatisiert und mit Auszeichnungen für die jeweilige Wortart (sog. POS-Tags, für part of speech) versehen. Darüber hinaus gibt es zu jedem Satz den Link zu der Website, auf der er gefunden wurde1, und geographische Daten, die aus den jeweiligen IPs gewonnen wurden. Letztere sind natürlich insofern relativ unzuverlässig, als sie keine Auskunft darüber geben, ob die Person, die den jeweiligen Satz verfasst hat, tatsächlich dort wohnt; und selbst wenn dies der Fall sein sollte, bedeutet es nicht zwangsläufig, dass sie auch dort sozialisiert wurde.2 Im populärwissenschaftlichen, aber sehr empfehlenswerten „Sprachlog“ hat jedoch Susanne Flach gezeigt, dass sich die Geo-IP-Daten durchaus – in begrenztem Maße und mit der gebotenen Vorsicht – für dialektologische Fragestellungen nutzen lassen.3 Ein exemplarischer Vergleich zwischen COW-Daten und Daten aus dem „Atlas der Alltagssprache“, der die regionale Verteilung solcher Alternanzen auf Grundlage von Internetumfragen kartiert, legt nahe, dass sich die geographische Distribution der Korpusdaten zumindest in den beispielhaft untersuchten Fällen ungefähr mit jener, die im Rahmen des AdA-Projekts erhoben wurde, deckt. So zeigen die AdA-Daten, dass im Falle der Alternanz benutzen vs. benützen die umgelautete Form ein Phänomen ist, das sich weit überwiegend im oberdeutschen Sprachraum, also im Süden des deutschen Sprachgebiets, findet. Diese areale Verteilung wird auch in Fig. 9 (links) deutlich, die auf einer Stichprobe aus DECOW14AX beruht. Mit Hilfe des (mittlerweile überholten) Online-Tools Colibri2 (Schäfer 2015) wurden Stichproben von jeweils 10.000 Tokens für benützen und benutzen genommen. Ungefähr ein Drittel der Daten konnte anhand der Geo-IP einem Ort zugeordnet werden (3.514 für benützen, 3.591 für benutzen). Allerdings bildet die Grafik lediglich für jeden in den Daten identifizierbaren Ort den Anteil der umgelauteten Variante ab (dargestellt anhand der Farbintensität: je dunkler, desto mehr benützen), ohne dass die enormen Frequenzunterschiede zwischen den einzelnen Orten berücksichtigt werden. Die weitaus meisten Belege stammen – wenig überraschend – aus Ballungsgebieten wie Berlin (Platz 1 bei benutzen), der Region um Düsseldorf (Höst bei Düsseldorf belegt Rang 2), Nürnberg (Platz 3) oder Hamburg (Platz 4). Damit ist auch zu erklären, dass sich in der Region um Berlin sehr viel häufiger benützen findet als anderswo in der nördlichen Hälfte Deutschlands – die Grundgesamtheit ist schlichtweg höher. Auch für die im Österreichischen verbreitete Variante Aufnahmsprüfung, deren Verteilung die rechte Hälfte von Fig. 9 auf Grundlage von DECOW14AX-Daten zeigt, finden sich in Berlin immerhin 2 Belege. Von den 5.060 Belegen für Aufnahmeprüfung und 77 Belegen für Aufnahmsprüfung, die mit Hilfe von Colibri2 gefunden wurden, können 2.094 bzw. 30 einem Ort zugeordnet werden, wobei sich deutlich die areale Konzentration der Variante mit Fugen-s im österreichischen Raum zeigt. Diese Stichproben lassen den Schluss zu, dass die Daten des COW-Korpus für die Ermittlung der arealen Verteilung sprachlicher Varianten zumindest nicht ganz unbrauchbar sind.
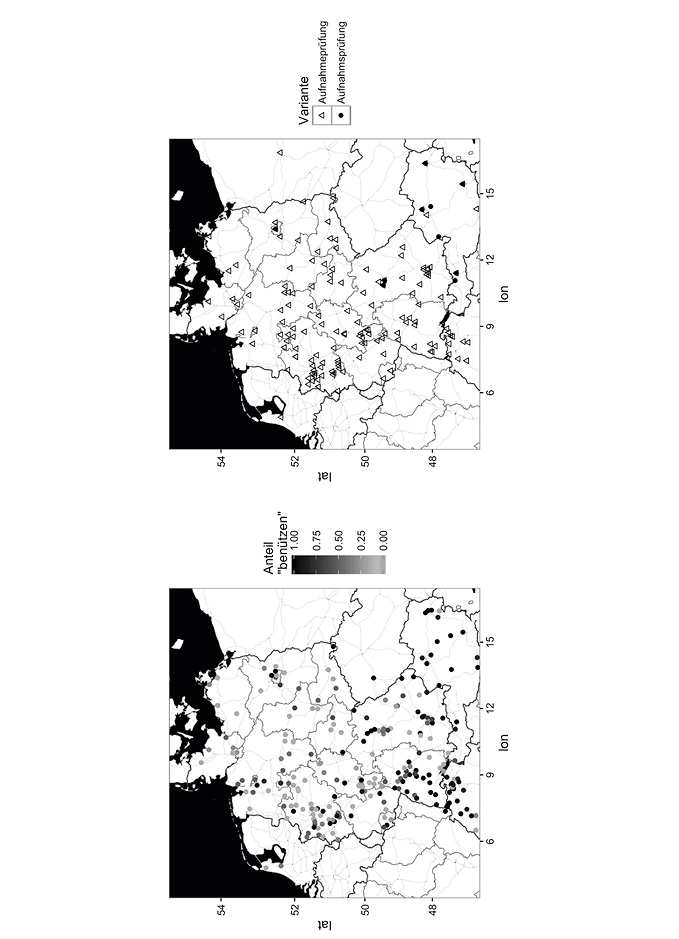
Fig. 9: Links: benutzen vs. benützen in einer Stichprobe aus dem Webkorpus DECOW14AX. Rechts: Aufnahmeprüfung vs. Aufnahmsprüfung in einer Stichprobe aus DECOW14AX.
Ein zweites Webkorpus ist WaCkY, dessen deutsches Subkorpus deWAC 1,7 Milliarden Tokens umfasst. Ein wesentlicher Vorteil von WaCkY ist, dass es derzeit ohne vorherige Anmeldung genutzt werden kann4, während für DECOW eine Freischaltung erforderlich ist. Bei der Erarbeitung von WaCkY wurde ähnlich vorgegangen wie bei der Zusammenstellung der COW-Korpora: Um sicherzustellen, dass das Korpus im Hinblick auf Genre und Register möglichst breit gefächert ist, wurden zufällig generierte Paare aus zufällig ausgewählten Wörtern (fürs Deutsche u.a. mittelfrequente Wörter aus der „Süddeutschen Zeitung“) als sog. „Seeds“ gewählt, nach denen dann mit Hilfe einer Suchmaschine gesucht wurde (vgl. Baroni et al. 2009). Nach dem sog. „Crawlen“ wurde dann der Boilerplate-Text, also standardisierte, immer wieder verwendete Textelemente, entfernt (z.B. die Navigationsleiste einer Homepage, vgl. Schäfer & Bildhauer 2013: 47f.). Dadurch wird vermieden, dass bestimmte Wörter und Wortkombinationen wie etwa „Zur Startseite“ in den Daten überrepräsentiert sind.
Zum Weiterlesen
Passend zu den verwegenen Namen der Korpora, ist das Gebiet „Web als Korpus“ noch immer eines, auf dem viel Pioniergeist herrscht – deshalb gibt es derzeit auch wenig Literatur, die „Best Practice“-Empfehlungen zum Umgang mit den Massen an Daten gebündelt präsentieren könnte. Lemnitzer & Zinsmeister (2015) gehen kurz und eher kritisch auf Webkorpora ein; ansonsten empfiehlt es sich, einige Aufsätze zu lesen, die von den Korpora Gebrauch machen – auf corporafromtheweb.org gibt es eine Übersicht.
Auf der Suche nach dem perfekten Korpus
Welches Korpus ist das richtige? Lohnt es sich, ein eigenes Korpus zusammenzustellen, oder sollte man auf ein bestehendes Korpus zurückgreifen? Die Antwort auf diese Fragen hängt immer von der jeweiligen Fragestellung ab. Daher gilt stets das Prinzip: Zuerst die Fragestellung – dann die Methode.
Die Vielfalt der Abfragesysteme und die jeweiligen Einschränkungen bezüglich Abfrage- und Exportmöglichkeiten schaffen leider teilweise unnötige Hürden bei der Korpusnutzung. Das liegt zum Teil auch am derzeit noch sehr restriktiven deutschen Urheberrecht, das leider dazu führt, dass ernstzunehmende Korpuslinguistik in Deutschland teilweise nur in rechtlichen Grauzonen möglich ist. Zum Beispiel machen die Zugangsbeschränkungen des Abfragesystems COSMAS II das größte Korpus der deutschen Gegenwartssprache, das DeReKo, für viele quantitativ basierte korpuslinguistische Methoden faktisch unbrauchbar. Die folgenden Anmerkungen werden wahrscheinlich für die meisten Studierenden irrelevant sein, können sich aber ggf. für Promovierende als hilfreich erweisen, die in etwas größerem Rahmen ein eigenes Korpus erstellen. Wer in die Verlegenheit kommt, ein eigenes Korpus zu erstellen und zu publizieren, sollte aus Rücksicht auf spätere Benutzer idealerweise
1 sofern es die urheberrechtliche Lage zulässt, die Daten vollständig in einem programm- und plattformunabhängigen Dateiformat (z.B. .txt-Dateien für einfache, unannotierte Texte; XML für Text und Annotationen; keine proprietären Formate wie z.B. .doc(x) oder .xls(x)!) der Forschungsöffentlichkeit zugänglich machen. In vielen Fällen ist das nicht möglich, weil die Rechteinhaber nicht möchten, dass ihre Texte vollständig zugänglich sind. In diesem Fall ist der nächste Punkt umso wichtiger – aber auch unabhängig davon, ob man die Rohdaten zur Verfügung stellen kann oder nicht, sollte man idealerweise
2 das Korpus über eine benutzerfreundliche Schnittstelle zugänglich machen, die reguläre AusdrückeReguläre Ausdrücke unterstützt und den Export möglichst vieler Belege im Key Word in Context-Format (KWIC) erlaubt. Ein gutes Vorbild sind hier die COW-Korpora: Sie machen von der quelloffenen NoSketchEngine Gebrauch, in der man die recht intuitive und einfach zu lernende CQP-Syntax verwenden kann. Auch lassen sich bis zu 100.000 Belege im KWIC-Format exportieren, was im Vergleich zu anderen Korpora eine erfreulich hohe Zahl ist. Erfreuliche Entwicklungen sind auch beim DWDS und bei den „Deutsch Diachron Digital“-Korpora zu verzeichnen. Das DWDS hat zwar eine m.E. etwas weniger intuitive, aber ähnlich mächtige Suchabfragesprache und verfügt seit kurzem über sehr nützliche und bedienerfreundliche Exportoptionen. Die Referenzkorpora Altdeutsch und Mittelhochdeutsch nutzen das Korpusabfragesystem ANNIS, das sich für Korpora mit komplexer Mehrebenenannotation anbietet. Erfreulicherweise steht hier neben einer Reihe anderer Exporter mit teils sehr simplem, teils sehr komplexem Output seit kurzem auch die Möglichkeit des KWIC-Exports zur Verfügung (mit dem TextColumnExporter ab Version 3.5; im Referenzkorpus Altdeutsch bereits implementiert, im Referenzkorpus Mittelhochdeutsch – Stand September 2017 – noch nicht).

Wer Korpuslinguistik betreiben möchte, darf keine Angst davor haben, sich mit neuer Software und idealerweise mit Programmiersprachen vertraut zu machen. Für AnfängerInnen ist die Hemmschwelle oft hoch, aber die Tutorials im Begleitmaterial versuchen, Ihnen den Umgang mit Korpora und die Auswertung von Korpusdaten so einfach wie möglich zu machen. Ebenfalls sehr empfehlenswert zum Einstieg ins korpuslinguistische Arbeiten ist die Website von Noah Bubenhofer (http://www.bubenhofer.com/korpuslinguistik/kurs/, zuletzt abgerufen am 20.09.2017).
Folgende Programme sollten Sie auf jeden Fall installieren, wenn Sie korpuslinguistisch arbeiten möchten:
einen guten Texteditor. Die bei Windows und Mac nativ vorhandenen Texteditoren sind für korpuslinguistische Zwecke suboptimal. Ich empfehle Notepad++ für Windows und TextWrangler für Mac, für Linux gibt es z.B. Notepadqq. Alle drei sind kostenlos erhältlich.
ein Tabellenkalkulationsprogramm. Die meisten von Ihnen werden mit Microsoft Excel vertraut sein; eine gute freie Alternative ist LibreOffice Calc. Während Letzteres nicht alle Funktionen von Excel umfasst, hat es den Vorteil, dass es etwas besser mit Unicode-Sonderzeichen umgehen kann, denen wir bei der Arbeit mit historischen Textdaten häufig begegnen.
Das Statistikprogramm R ist mittlerweile in der (quantitativen) Korpuslinguistik zum Standard geworden, wenn es um die Auswertung von Daten geht. Aber auch für die Aufbereitung von Daten eignet es sich hervorragend, auch wenn man relativ viel Zeit braucht, um sich einzuarbeiten, wenn man noch keine Programmiererfahrung hat. Als grafische Benutzeroberfläche empfehle ich RStudio, ebenfalls kostenlos erhältlich. Die Skripte im digitalen Begleitmaterial lassen sich allesamt weitgehend ohne jegliche Vorkenntnisse benutzen. Wer sich tiefer einarbeiten möchte, kann z.B. zu Gries (2016) greifen.
Daten zu sammeln und auszuwerten, ist immer nur der erste Schritt im Forschungsprozess. Ebenso wichtig ist das Berichten der Ergebnisse. Dabei sollten die Ergebnisse so aufbereitet werden, dass die für die jeweilige Fragestellung relevanten Befunde (und nur diese) konzise, zugleich aber maximal informativ präsentiert werden. Folgende Prinzipien sollten dabei beachtet werden:
1 Ergebnisorientierung. Der Weg von der Hypothese zur Korpusrecherche und ihrer Analyse ist oft kein geradliniger: So kann es vorkommen, dass verschiedene Suchanfragen oder verschiedene Annotationsvarianten ausprobiert und wieder verworfen werden. Dieser Prozess ist in vielen Fällen zwar nicht uninteressant, für die Leserin aber in aller Regel nicht relevant. Stattdessen sollten konzise und an der Fragestellung orientiert die wichtigsten W-Fragen beantwortet werden: Was wurde untersucht? Warum wurde es untersucht (Motivation, Fragestellung)? Wie genau wurde dabei vorgegangen? Welche Ergebnisse wurden erzielt? Was sagen uns diese Ergebnisse?
2 Nachvollziehbarkeit. Die Durchführung und die Ergebnisse sollten so berichtet werden, dass der Leser sie nachvollziehen und ggf. auch selbst replizieren kann. Um die Replizierbarkeit zu gewährleisten, muss auf jeden Fall präzise angegeben werden, mit welchem Korpus gearbeitet wurde und wonach genau in dem Korpus gesucht wurde. Um sicherzustellen, dass der Leser die Ergebnisse auch nachvollziehen kann, ohne die Studie gleich selbst replizieren zu müssen, ist es unter anderem wichtig, stets Grundgesamtheiten zu nennen (wie groß ist mein Korpus / meine Stichprobe), anstatt nur mit relativen Frequenzen zu arbeiten. So ändert sich die Aussagekraft eines Befunds wie „Das Wort Weib wird im Korpus in 40 % der Fälle neutral gebraucht und in 60 % der Fälle mit negativer Konnotation“ drastisch, je nachdem, ob zehn Belege oder tausend Belege analysiert wurden.
3 Leserfreundlichkeit. Die Ergebnispräsentation sollte einerseits so vollständig wie möglich sein, andererseits jedoch sollte gleichsam die für die Fragestellung relevante „Essenz“ der Befunde leserfreundlich aufgezeigt werden. Dies gelingt am besten über die graphische Aufbereitung der Resultate. So zeigt das Balkendiagramm in Fig. 5 auf einen Blick den Unterschied zwischen den beiden Textsorten hinsichtlich der Erwähnung von Begriffen aus dem Wortfeld „Süßwaren“ und ist somit sehr viel leserfreundlicher als beispielsweise eine Liste an Frequenzen oder Prozentwerten, die gerade bei zahlreichen Analysen auch sehr ermüdend sein kann.
4 Reproduzierbarkeit. Die Korpusrecherche sollte für den Leser oder die Leserin nicht nur nachvollziehbar sein, sondern er oder sie sollte auch in die Lage versetzt werden, sie selbst durchzuführen. Daher setzt sich immer mehr die Praxis durch, sämtliche Daten, die einer Studie zugrundeliegen, öffentlich zugänglich zu machen. Dadurch wird sichergestellt, dass zum einen die Richtigkeit einer Korpusanalyse überprüft werden kann und zum anderen neue Methoden und Analyseansätze auf bestehende Daten angewandt werden können. Für linguistische Datensätze gibt es mittlerweile auch spezialisierte Repositorien wie das Tromsø Repository for Language and Linguistics (https://opendata.uit.no/dataverse/trolling). Viele Linguistinnen und Linguisten nutzen auch nicht spezifisch sprachwissenschaftliche Repositorien wie Figshare oder GitHub.
2.2.3 Reflexe des Sprachwandels im Gegenwartsdeutschen: Fragebogenstudien und Experimente
Die historische Linguistik ist auf Korpusuntersuchungen sowie auf die komparative Methode angewiesen, weil sich Sprecherinnen des Frühneuhochdeutschen oder gar des Germanischen oder Indoeuropäischen nicht mehr befragen lassen. Auch für die Gegenwartssprache gibt es gute Argumente, einen beobachtenden Zugang zu wählen, anstatt Sprecherinnen und Sprecher direkt nach ihrem Sprachverhalten zu befragen (oder gar das eigene Sprachverhalten als ausschlaggebend zu betrachten). In einem Diskussionspapier von Arppe et al. (2010) spricht sich beispielsweise Martin Hilpert dagegen aus, Grammatikalitäts- bzw. Akzeptabilitätsurteile zu erfragen – unter anderem deshalb, weil metasprachliche Einschätzungen nicht zwangsläufig das tatsächliche sprachliches Wissen repräsentieren müssen, zu dem wir als Sprecherinnen und Sprecher (und natürlich auch als Sprachwissenschaftler) keinen unmittelbaren Zugang haben. Man könnte noch hinzufügen, dass unterschiedliche Sprecher womöglich unterschiedliche Maßstäbe anlegen. Wenn ich verschiedene Personen befrage, wie akzeptabel für sie eine Form wie dem Vater sein Auto in der Alltagssprache ist, so werden womöglich einige, die diese Form selbst gebrauchen, sie als inakzeptabel kategorisieren, da sie wissen, dass sie als umgangssprachlich bzw. dialektal stigmatisiert ist. Dagegen führt jedoch Antti Arppe im gleichen Diskussionspapier das Argument ins Feld, dass das Fällen (meta)sprachlicher Grammatikalitäts- und Akzeptabilitätsurteile genauso eine sprachliche Aktivität sei wie Sprachproduktion und -rezeption. Auch das kennen wir aus unserer Alltagserfahrung: Wenn jemand tiefstes Sächsisch oder Schwäbisch spricht, bringen wir diese Person schnell mit der jeweiligen Region in Verbindung – und auch mit all den Stereotypen, die wir über Sachsen oder Schwaben haben. Und wenn jemand eine aus unserer Sicht „falsche“ grammatische Form gebraucht, können wir oft gar nicht anders, als den Fehler in Gedanken zu korrigieren. Folgerichtig gilt es bei Studien, die auf Grammatikalitäts- und Akzeptabilitätsurteilen fußen, zwar immer eine Reihe von möglichen Störfaktoren zu bedenken, doch können sie sich für viele Fragestellungen als äußerst aufschlussreich erweisen.
Wie aber – um auf die eingangs gestellte Frage zurückzukommen – können Fragebogenstudien und Experimente zur sprachgeschichtlichen Forschung beitragen? Hier müssen wir uns vor Augen führen, dass Sprachwandel (zumindest in aller Regel) kein sprunghafter, sondern ein kontinuierlicher Prozess ist. Daher hängen Sprachwandel und sprachliche Variation untrennbar zusammen. Einerseits bildet sprachliche Variation die Keimzelle des Sprachwandels, andererseits führt Sprachwandel seinerseits zu Variation. Wenn eine Sprecherin eine neue Form benutzt (Innovation), die sich dann allmählich in der Sprachgemeinschaft ausbreitet (Diffusion), so entsteht dadurch Variation, wobei zunächst alte und neue Form miteinander konkurrieren. Ein einfaches Beispiel: Noch bis ins 19. Jh. war die Form in Ansehung deutlich verbreiteter als ihr heutiges Äquivalent in Anbetracht. Eine einfache Suche im Google ngram Viewer1 – der zwar als Korpus problematisch ist, aber durch die Nutzung der umfangreichen GoogleBooks-Daten eine ungeheuer große Datenbasis hat – zeigt, wie die neue Form um die Wende vom 19. zum 20. Jahrhundert die alte überholt (s. Fig. 10). Die Phase, in der eine neue Form sich durchsetzt und dabei ggf. eine alte verdrängt, nennt man Approbationsphase (vgl. Bechmann 2016: 74). Weil der Prozess graduell ist, existieren eine Zeitlang mehrere Formen nebeneinander. Bechmann (2016: 158) bringt es auf den Punkt: „Gegenwärtiges ist immer Gewordenes aus Gewesenem.“
Dabei kann es zu Zweifelsfällen kommen, bei denen Sprecherinnen und Sprecher unsicher sind, welche von (mindestens) zwei möglichen Formen die standardsprachlich „richtige“ ist (vgl. Klein 2003, 2009). So schwanken Sprecher heute beispielsweise zwischen Pluralformen mit und ohne Umlaut: die Wagen vs. die Wägen. Möglicherweise fiel Sprecherinnen vor etwas über 100 Jahren auch die Wahl zwischen in Ansehung und in Anbetracht nicht leicht. Nübling (2012: 66) vergleicht solche Zweifelsfälle mit „Beben“, die auf tiefgreifende Veränderungen zurückgehen. Fragebogenstudien können somit gleichsam als „Seismograph“ für solche Veränderungen gesehen werden und können helfen, Fragen zu beantworten wie:
Welche alternativen Formen gibt es?
Wird eine der Formen häufiger gebraucht?
Wird eine der Formen in bestimmten Kontexten häufiger gebraucht? (z.B. Registervariation: eine Form findet sich eher in formellen Kontexten, eine andere eher in mündlich bzw. umgangssprachlich geprägten)
Wird eine der Formen in bestimmten Regionen oder Dialektgebieten häufiger gebraucht?
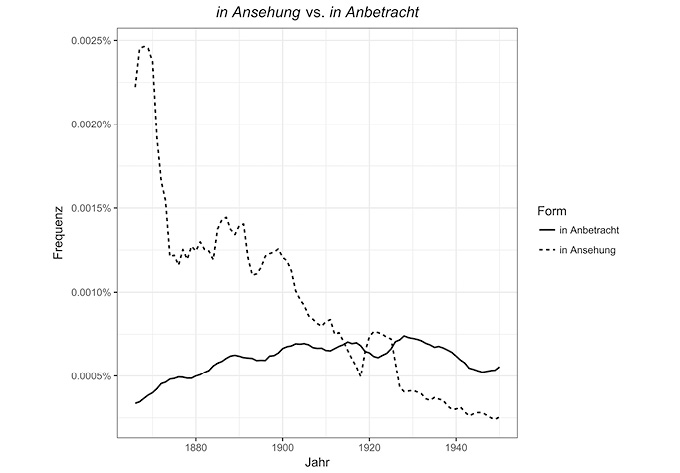
Fig. 10: Frequenz von in Ansehung vs. in Anbetracht im Google Ngram Viewer. (Anteil der jeweiligen Form an allen Tokens im GoogleBooks-Korpus.)
Dieser letztgenannten diatopischen Variation widmen sich beispielsweise Sprachatlanten. Pionierarbeit auf diesem Gebiet hat Georg Wenker (1852–1911) mit seinem „Sprachatlas des Deutschen Reichs“ geleistet, der über das Marburger Forschungszentrum Deutscher Sprachatlas unter www.regionalsprache.de vollständig online abrufbar ist. Mit Hilfe einer Reihe von Sätzen, die er von Volksschullehrern aus dem gesamten damaligen Deutschen Reich ausfüllen ließ, konnte Wenker vor allem die Verteilung lautlicher Varianten kartieren. Aber auch lexikalische Variation zeigt sich in seinen Karten, etwa zwischen Dienstag, Aftermontag (im Ostschwäbischen) und Ertag (im Bairischen) oder zwischen Buddel im Niederdeutschen und Mecklenburgisch-Vorpommerschen einerseits und Flasch(e) in anderen Gebieten.
Im weiteren Verlauf dieses Kapitels werfen wir zunächst einen näheren Blick auf die Methodik von Fragebogenstudien, ehe wir einen Schritt weitergehen und das Potential behavioraler Experimente, die über reine Befragungen hinausgehen, für linguistische Fragestellungen und insbesondere für die Zweifelsfallforschung erkunden.
Fragebogenstudien
Während der Beginn der modernen Umfragenforschung, der naturgemäß insbesondere in Disziplinen wie der Soziologie ein zentraler Stellenwert zukommt, laut Hippler & Schwarz (1996: 726) in die 30er-Jahre des 20. Jh. zu datieren ist, haben wir am Beispiel von Georg Wenkers Deutschem Sprachatlas bereits gesehen, dass die systematische Sammlung von Daten durch Befragung von Informanten bereits im 19. Jh. zum Methodenrepertoire der Sprachwissenschaft gehörte. Seither haben sich die Möglichkeiten der Befragung schon allein durch den technischen Fortschritt tiefgreifend verändert. Dadurch sind natürlich auch die methodischen Anforderungen, die heute an Fragebogenstudien gestellt werden, deutlich rigoroser als noch zu Beginn der Umfragenforschung oder gar zu Wenkers Zeiten. Daher wäre es verfehlt anzunehmen, dass man einen Fragebogen „samstagnachmittags beim Kaffeetrinken“ erstellen könne, wie Porst (2014: 13) die ironische Bemerkung eines Kollegen zitiert.
Porst (1996: 738) definiert einen Fragebogen als