





- -
- 100%
- +
Es ist leicht einzusehen, dass der Schätzfehler für einen statistischen Kennwert mit zunehmender Größe der Stichprobe immer kleiner wird und schließlich gegen Null geht, wenn alle möglichen Fälle in die Berechnung einbezogen sind (Abb. 3.10).
| Abb 3.10
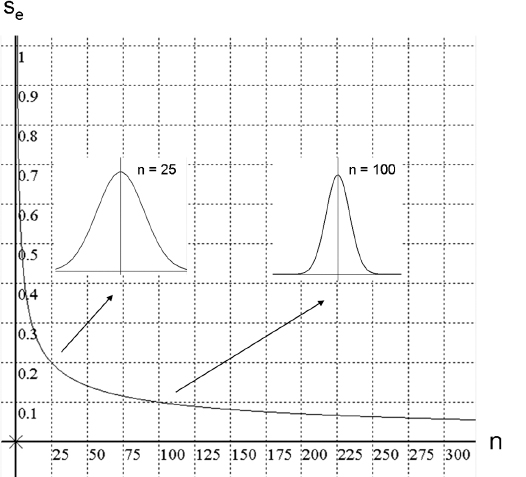
Der Schätzfehler (se ) für die Bestimmung des Mittelwertes einer Population von Fällen aufgrund einer Stichprobe ist eine Funktion der Stichprobenstreuung (s) und des Stichprobenumfanges (n):
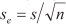
lat. inferre: hineintragen
Die mathematisch begründeten Methoden der Inferenzstatistik sollen also eine Einschätzung erlauben, ob überhaupt und in welchem Ausmaß statistische Resultate von Stichproben auf die jeweilige Population übertragbar sind.
Merksatz
Inferenzstatistische Verfahren zielen darauf ab, den Grad der Allgemeingültigkeit von Gesetzmäßigkeiten zu prüfen, die auf Basis von Stichproben gewonnen werden.
Wenn die Wahrscheinlichkeit dafür, dass bestimmte Variablenrelationen zufällig zu erklären sind, einen vereinbarten Wert unterschreitet (z.B. p = 0,05, p = 0,01 oder p = 0,001), dann spricht man von statistischer Signifikanz des Ergebnisses. Bortz und Döring (1995, 27) definieren statistische Signifikanz als ein „per Konvention festgelegtes Entscheidungskriterium für die vorläufige Annahme von statistischen Populationshypothesen“. Wenn also ein statistisches Ergebnis nur mehr zu 5 % (oder weniger) durch Zufallsprozesse erklärt werden kann, wird es als statistisch signifikant angesehen („überzufällig“ oder „unterzufällig“). Die restliche, für eine Zufallserklärung verbleibende Unsicherheit von 5 % (oder weniger) nennt man Irrtumswahrscheinlichkeit („Fehler 1. Art“, „Alpha-Fehler“), die dazugehörige den Zufallsprozess charakterisierende Annahme (über die Datenverteilung) heißt Nullhypothese.
Da die praktische Bedeutsamkeit eines signifikanten Ergebnisses aber auch von dessen Effektstärke abhängt, müssen abgesehen von der Nullhypothese auch Alternativhypothesen statistisch getestet werden. Das Ausmaß, in dem die Datenverteilungen mit den Vorhersagen einer Alternativhypothese übereinstimmen, wird als Teststärke (engl. power) bezeichnet. Um diese berechnen zu können, ist es nötig, die jeweilige Alternativhypothese zu spezifizieren, indem man die erwartete Effektgröße präzisiert, d.h. schätzt, wie stark die jeweilige unabhängige Variable auf die abhängige Variable einwirken dürfte. Der Vorteil einer solchen Vorgangsweise besteht vor allem darin, dass man nicht nur vage auf „Über- oder Unterzufälligkeit“ von statistischen Ergebnissen schließt, sondern sogar die Wahrscheinlichkeit bestimmen kann, mit der die Daten für die Alternativhypothese sprechen.
Forschungsmethoden der Psychologie| 3.7 Laborexperiment| 3.7.1Mittels eines Experiments ist es möglich, hypothetische Wirkfaktoren gezielt zu manipulieren, um ihre Auswirkungen unter verschiedenen Bedingungen zu analysieren. Experimente werden bevorzugt zur Prüfung von Kausalhypothesen eingesetzt (Stapf, 1987). Im Experiment wird eine künstliche Realität konstruiert, um die vermuteten Einflussfaktoren in ihrer Wirksamkeit unter Abschirmung von möglichen Störeinflüssen zu untersuchen.
Häufig wird in psychologischen Experimenten der (den) Experimentalgruppe(n) (Versuchsbedingungen) eine Kontrollgruppe (Kontrollbedingung) gegenübergestellt. Den Fällen der Experimentalgruppen sind solche Ausprägungen der unabhängigen Variablen (Ursachenvariablen) zugeordnet, von denen ein Effekt auf die abhängigen Variablen (Wirkungsvariablen) erwartet wird, während den Fällen der Kontrollgruppe Ausprägungen der unabhängigen Variablen zugeteilt sind, denen kein systematischer Effekt zugeschrieben wird. Diese Gruppe dient somit nur dazu, Veränderungen zu erfassen, die entweder auf natürliche Weise auftreten (Zeiteffekte, Gewöhnungsprozesse etc.) oder durch die experimentellen Umstände selbst zustande kommen, nämlich durch die künstliche Situation oder den Eindruck, beobachtet zu werden.
Die künstliche Realität des Experiments ist einerseits ein Vorteil, weil durch die Beseitigung von Störeinflüssen der Zusammenhang zwischen unabhängigen und abhängigen Variablen klarer erkannt werden kann (hohe „interne Validität“), andererseits aber auch ein Nachteil, weil die Ergebnisse nur mit Vorsicht auf den Alltag übertragbar sind (geringe „externe“ bzw. „ökologische Validität“).
Ein wesentliches Merkmal psychologischer Experimente ist die Randomisierung. Durch die Randomisierung sollen sich Störeffekte ausmitteln, die eventuell durch unausgewogene Stichproben zustande kommen. In der zuvor erwähnten Studie über die Wirkung des Alkohols auf das Fahrverhalten (Box 3.1) würden zum Beispiel die sich meldenden Versuchspersonen per Zufall den Gruppen mit unterschiedlicher Alkoholaufnahme zugewiesen werden.
Die Störeffekte in psychologischen Experimenten haben im Wesentlichen drei verschiedene Quellen (Gniech, 1976):
Randomisierung meint die zufällige Zuordnung von Personen (oder Gruppen) zu den jeweiligen Ausprägungen der unabhängigen Variablen.
1. Versuchssituation: Der sogenannte „Aufforderungscharakter“ eines experimentellen Umfelds, nämlich die Art der Information über den Zweck der Untersuchung, die Rahmenbedingungen, die Art der Instruktion, die gestellten Fragen und Ähnliches hinterlassen bei den Versuchspersonen Eindrücke, die ihr experimentell induziertes Verhalten beeinflussen können.
2. Versuchspersonen: Eine unüberlegte, nicht randomisierte Auswahl der Stichprobe kann Verfälschungen in den Ergebnissen bewirken. Ein nicht zu unterschätzendes Problem bei der Interpretation von Untersuchungsergebnissen ist zum Beispiel die oft notwendige Beschränkung der Teilnahme auf Freiwilligkeit und das Ausscheiden von Teilnehmenden aus dem Experiment („drop out“), wodurch natürlich die erwünschte Zufallsauswahl einer Stichprobe beeinträchtigt ist. Personen, die sich freiwillig für ein Experiment melden, sind im Allgemeinen besser gebildet, haben einen höheren gesellschaftlichen Status, sind stärker sozial orientiert und haben ein stärkeres Bedürfnis nach Anerkennung (Rosenthal & Rosnow, 1975; zit. nach Gniech, 1976). Natürlich wirken sich auch Einstellungsunterschiede der Teilnehmerinnen und Teilnehmer gegenüber der Untersuchung aus, je nachdem, ob es sich um kooperierende, sabotierende oder neutrale Versuchspersonen handelt.
3. Versuchsleitung: Vonseiten der Forscherinnen und Forscher sollten beobachterabhängige Urteilsverzerrungen (engl.: observer bias) beachtet werden, die durch persönliche Motive und Erwartungen entstehen. Besonders störend sind unbewusste Einflussnahmen (z.B. über nonverbale Kommunikation) im Sinne eigener theoretischer Vorstellungen („Erwartungseffekte“, „Rückschaufehler“, Selbsterfüllende Prophezeiung). In Experimenten mit Volksschulkindern (Box 3.4) konnte etwa nachgewiesen werden, dass Lehrpersonen gegenüber fremden Kindern, die ihnen aufgrund von Testresultaten als angeblich begabt ausgewiesen wurden (als „Spätentwickler“), sich sympathischer, förderlicher und entgegenkommender verhielten, sodass sie mit ihrem Verhalten de facto dazu beitrugen, die Fähigkeiten der Kinder zu steigern (Rosenthal & Jacobson, 1968).
lat. placebo: „Ich werde gefallen.“
Dass Erwartungshaltungen, zum Beispiel hinsichtlich der Wirksamkeit eines Medikamentes, beachtliche Auswirkungen haben können, ist seit Langem aus der Medizin unter der Bezeichnung Placebo-Effekt bekannt. Darunter versteht man die positive Wirkung auf Befinden oder Gesundheit ausgehend von medizinisch unwirksamen Substanzen – sogenannten „Placebos“ (z.B. Milchzucker, Stärke, Salzlösungen) –, allein durch Herstellung einer Erwartung von Wirksamkeit.
| Box 3.4 Selbsterfüllende Prophezeiung
Die Selbsterfüllende Prophezeiung wird auch Pygmalion-Effekt genannt, nach dem Bildhauer der griechischen Mythologie, der die Statue einer perfekten Frau schuf („Galatea“) und sie durch seinen festen Glauben und seine Sehnsucht nach ihr zum Leben erweckte (Göttin Aphrodite soll allerdings mitgeholfen haben).
In einem Experiment der Sechzigerjahre waren 18 Klassen einer Volksschule einbezogen. Bei allen Schülerinnen und Schülern wurde ein nonverbaler Intelligenztest durchgeführt, den man als Indikator für eine zu erwartende intellektuelle Entwicklung der Kinder in den nächsten acht Monaten ausgab. Aus allen Klassen wurden 20 % der Kinder zufällig (!) ausgewählt, die den Lehrpersonen mit dem Hinweis genannt wurden, dass von diesen Kindern aufgrund des durchgeführten Tests in der nächsten Zeit ein intellektueller Fortschritt zu erwarten sei. Nach acht Monaten zeigten die mit dem positiven Vorurteil bedachten Kinder im Intelligenztest deutliche Verbesserungen! Der gleiche Effekt konnte auch in Tierexperimenten nachgewiesen werden (Rosenthal, 2002).
Das Gegenteil vom Placebo-Effekt ist der Nocebo-Effekt, nämlich die durch Erwartung hervorgerufene negative Auswirkung eines eigentlich unwirksamen Medikaments oder einer Behandlung.
Um die genannten Artefakte in Experimenten zu reduzieren, werden Doppel-blind-Verfahren eingesetzt, bei denen weder die Versuchspersonen noch die unmittelbar das Experiment betreuenden Forscherinnen und Forscher über die Art der experimentell gesetzten Einwirkungen Bescheid wissen dürfen. Da natürlich auch in Blindstudien die Probandinnen und Probanden über die Intention einer Studie Vermutungen entwickeln, müssen in der psychologischen Forschung manchmal auch Täuschungen eingesetzt werden. Selbstverständlich sind diese nach Ende des Experiments aufzuklären.
Merksatz
In einem Experiment werden unter abgeschirmten Bedingungen die Effekte (abhängige Variablen) systematisch variierter Wirkfaktoren (unabhängige Variablen) registriert, wobei durch eine zufällige Zuteilung der Fälle zu den Bedingungen der Wirkfaktoren etwaige Verfälschungen der Ergebnisse minimiert werden sollen.
Experimente sowie andere Forschungsdesigns können sowohl als Querschnittuntersuchung (engl.: cross sectional study) als auch als Längsschnittuntersuchung (engl.: longitudinal study) durchgeführt werden. Bei der häufig eingesetzten Querschnittstudie werden an einzelnen Fällen (Personen, Gruppen, Situationen etc.) die interessierenden Variablen nur einmalig erhoben, sodass strukturelle Gesetze von Variablen analysiert werden können, während bei einer Längsschnittstudie zwei oder mehr Datenerhebungen zu den gleichen Variablen stattfinden und somit auch deren zeitliche Dynamik erfassbar ist. Ein großer Vorteil der Längsschnittmethode liegt auch darin, dass intraindividuelle Veränderungen beobachtet werden können und Verfälschungen durch unausgewogene Stichproben, wie sie bei der interindividuellen Querschnittmethode vorkommen, reduziert sind (Daumenlang, 1987). Nachteilig ist hingegen über einen längeren Zeitraum der Schwund an Versuchspersonen und die Problematik der mehrmaligen Anwendung gleichartiger Testverfahren (Gefahr von „Serialeffekten“).
3.7.2 |QuasiexperimentMerksatz
Ein Quasiexperiment gleicht vom Aufbau her einem Experiment – mit dem Unterschied, dass die Fallzuordnung zu den Bedingungen nicht zufällig erfolgt.
Artefakt: In Psychologie und Nachrichtentechnik steht dieser Ausdruck für verfälschte Ergebnisse.
Diese Untersuchungstechnik gleicht vom Design her dem Experiment, nur verzichtet man auf eine zufällige Zuordnung der Versuchspersonen zu den Versuchs- bzw. Kontrollbedingungen und nimmt das Risiko von Stichprobeneffekten in Kauf. In manchen Forschungsbereichen ist eine zufällige Zuteilung zu den verschiedenen Bedingungen entweder nicht realisierbar oder ethisch nicht zu rechtfertigen; so etwa die zufällige Zuordnung von Schülerinnen und Schülern zu Schultypen, von Mitarbeiterinnen und Mitarbeitern zu Betrieben oder von Patientinnen und Patienten zu Behandlungsverfahren. Um die aus dem Verzicht einer Randomisierung resultierenden Artefakte zu kompensieren, werden in solchen Untersuchungen einerseits größere Probandengruppen angestrebt und andererseits zusätzliche Personenmerkmale erhoben, denen ein direkter oder indirekter Einfluss auf die abhängigen Variablen zugeschrieben werden kann. Zu diesen gehören die soziodemografischen Merkmale (Geschlecht, Alter, Schulbildung, Beruf ...), aber auch andere individuelle Charakteristika, die aufgrund ihrer Ungleichverteilung in den Bedingungen der unabhängigen Variablen zu systematischen Verfälschungen von Ergebnissen führen könnten. Mittels statistischer Korrekturverfahren lassen sich einige solcher Verfälschungen kompensieren bzw. aus den Ergebnissen herausrechnen („auspartialisieren“).
Feldforschung| 3.7.3Im Gegensatz zum Experiment versucht man in der Feldforschung, Phänomene unter möglichst natürlichen Bedingungen zu beobachten und zu erklären. Dem Vorteil der Natürlichkeit steht hier der Nachteil gegenüber, dass Störvariablen weniger gut kontrolliert werden können. Da Forschungsphänomene „im Feld“ wesentlich komplexer in Erscheinung treten als im Labor, kommt bei der Feldforschung der Entwicklung von genauen und effizienten Beschreibungsmethoden sowie der Ausarbeitung von Verhaltensregeln zur optimalen Datengewinnung besondere Bedeutung zu (s. Flick et al., 1995).
Merksatz
Methoden der Feldforschung bezwecken eine Untersuchung von Phänomenen unter natürlichen Rahmenbedingungen bzw. unter minimierter versuchsbedingter Beeinflussung.
Sogenannte Fallstudien („single case studies“) sind häufig erste Erfahrungsquellen und als solche nur Anregungen für weitere Forschungstätigkeiten. Obwohl Forschungsphänomene durch Fallstudien hervorragend konkretisiert und plastisch vorstellbar gemacht werden können, mangelt es ihren Ergebnissen logischerweise an Verallgemeinerbarkeit.
Einen Katalog möglicher Verhaltensweisen in natürlichen Umweltbedingungen nennt man in der Verhaltensforschung Ethogramm, innerhalb dessen ein „behavior mapping“ charakterisiert, wer was wo tut (Hellbrück & Fischer, 1999).
Non-reaktive Verfahren bezwecken eine Analyse psychologischer Problemstellungen, ohne dass die untersuchten Personen bemer-ken, dass sie untersucht werden, was insbesondere bei Inhaltsanalysen von schriftlichen Dokumenten (z.B. Tagebüchern, Archiven), bei Auszählungen von Unfall-, Krankheits- und Fehlzeitstatistiken, Verkaufsstatistiken oder Abnützungen von Bodenbelägen, Pfaden oder Gebrauchsgegenständen („Spurenanalyse“) gut gelingt.
In der Feldforschung werden häufig, aber nicht ausschließlich, qualitative Methoden verwendet, weil diese flexibler auf die Eigenarten von Personen oder von Situationen anzupassen sind.
3.7.4 |Test und RatingMerksatz
Eine Standardisierung besteht aus Maßnahmen, die eine Vergleichbarkeit von verschiedenen Personen, Objekten, Situationen oder von Variablenwerten ermöglichen.
Ein Test ist ein wissenschaftlich normiertes und standardisiertes Prüfverfahren, welches stabile Eigenschaften eines komplexen Systems (Person, Gegenstand, Organisation) ermitteln soll. Unter Standardisierung versteht man Maßnahmen, aufgrund derer Situationen, Aktionen oder Objekte unter Bezugnahme auf Normen oder Regeln miteinander verglichen werden können. So etwa müssen in Experimenten Instruktionen und Rahmenbedingungen der Durchführung für alle Versuchspersonen standardisiert, d.h. als maximal ähnlich aufgefasst werden; Gleiches gilt für die Diagnostik, wo Tests verschiedenen Kandidatinnen oder Kandidaten vorgegeben werden. Bei standardisierten Fragebögen müssen die Fragen immer den gleichen Wortlaut haben, auch die möglichen Antworten sind fix vorgegeben (z.B. in Form von Antwortalternativen). Bei statistischen Auswertungen gelten Variablen dann als standardisiert, wenn ihre Werte als Differenz zu ihrem Mittelwert - und in Einheiten ihrer Streuung dargestellt werden (s. 3.6.1), wodurch auch inhaltlich sehr verschiedenartige Variablen miteinander in Relation gesetzt werden können. Bei Leistungs-, Intelligenz- oder Persönlichkeitstests bedeutet eine Standardisierung, dass die Ergebnisse der Probandinnen und Probanden auf die Verteilungen von sogenannten Referenz- oder Normstichproben bezogen sind.
Merksatz
Eine Skala soll Ausprägungen einer spezifischen Eigenschaft eines empirischen Sachverhaltes exakt (anhand von Zahlen) charakterisieren.
Da die in einem Test zu erfassenden Konstrukte aus Teilaspekten bzw. verschiedenen Inhaltskomponenten bestehen, setzen sich Tests aus entsprechend vielen Subtests bzw. Skalen zusammen, die jeweils ein homogenes Merkmal feststellen oder „messen“ sollen. Eine Skala ordnet somit empirischen Objekten (z.B. Personen) Zahlen zu, ähnlich wie dies bei der Längenmessung physikalischer Objekte anhand einer Meterskala geschieht (Niederée & Narens, 1996). Die Prüfung, ob zur Vermessung eines empirischen Objekts eine quantitative Skala akzeptiert werden kann, erfolgt auf Basis mathematisch-statistischer Messtheorien (s. auch 3.6.1, Skalenqualität).
engl. scale: Maßstab, Anzeige, Skala; ital. scala: Maßstab, Treppe, Leiter, Skala
Subtests oder Skalen bestehen selbst meist wieder aus zwei, drei oder mehr Elementen, den Items. Je nach inhaltlicher Orientierung des Tests oder der Skala können sich die Items aus Leistungsaufgaben, Fragen mit Antwortalternativen oder aus Skalierungen, nämlich Einschätzungen von Merkmalen anhand von Zahlen, zusammensetzen. Die Art der Reaktion einer Person auf ein Item wird über (Zahlen-)Symbole kodiert, welche unter Verwendung mathematisch-statistischer Modelle zu quantitativen Werten (z.B. Mittelwert über die einzelnen Items) für die einzelnen Skalen verrechnet werden. Je mehr Items für eine Skala zur Verfügung stehen, d.h., je mehr unabhängige elementare „Messinstrumente“ für eine Eigenschaft vorliegen, desto größer ist im Allgemeinen die Zuverlässigkeit der entsprechenden Skala.
engl. item: Datenelement, Einheit, Einzelheit, Element, Punkt, Nummer
Eine Aufzählung nach Bühner (2010) soll illustrieren, in welch verschiedenen Bereichen psychologische Tests eingesetzt werden: psychische und psychosomatische Störungen, Befindlichkeitsstörungen, Therapie- und Heilungsverlauf, Familien-, Ehe- und Erziehungsberatung, Berufsberatung und Personalauslese, Verkehrseignung (TÜV), Strafvollzug (Haftentlassung), Entwicklungsstörungen, Schulreife, Leistungsstörungen, Hochschuleignung, Produktbeurteilung, Einstellungs- und Motivationsmessung (Arbeitszufriedenheit, Leistungsmotivation) usw. „Die Auswahl und Interpretation von Test- und Fragebogenergebnissen zählen zu den Routineaufgaben in der späteren Berufspraxis“ von Psychologinnen und Psychologen (Bühner, 2010, 11).
Die Genauigkeit, die Aussagekraft und der Vorhersageerfolg von Testergebnissen hängen von sogenannten Gütekriterien der Tests ab. Allgemeine und unverzichtbare Gütekriterien von Datenerhebungsinstrumenten sind Objektivität, Reliabilität sowie Validität.
Die Objektivität eines Tests kennzeichnet die Unabhängigkeit seines Ergebnisses von der Person, die den Test durchführt. Sie ist besonders hoch, wenn verschiedene Testanwender zu gleichen Testergebnissen kommen. Dafür ist es allerdings nötig, dass die Anwenderinnen und Anwender fundierte testpsychologische Grundkenntnisse und Fertigkeiten besitzen (s. DIN-Norm 33430 für „Berufsbezogene Eignungsdiagnostik“, Hornke & Winterfeld, 2004; Bühner, 2010). Objektivitätsmängel können sowohl durch fehlende Sorgfalt bei der Testdurchführung als auch durch Unterschiede bei der Auswertung oder Interpretation entstehen.
Reliabilität bedeutet Zuverlässigkeit und Genauigkeit eines Tests und ist gegeben, wenn bei wiederholter Anwendung des Tests bei gleichen Probanden auch weitgehend gleiche Ergebnisse zustande kommen. Hinweise auf die Zuverlässigkeit von Tests bekommt man, indem man (1) einen Test (falls möglich) wiederholt vorgibt und dessen Ergebnisse auf Übereinstimmung prüft („Retest-Methode“), oder indem man (2) sogenannte Paralleltests, nämlich Tests mit gleicher Aussagekraft, entwickelt und deren Übereinstimmung bei ein und derselben Personengruppe kontrolliert („ParalleltestMethode), oder indem man (3) die Teile eines Tests auf Homogenität, d.h. auf inhaltliche Ähnlichkeit prüft („Konsistenzmethode“).
Die Validität (Gültigkeit), das wichtigste Gütekriterium eines Tests, gibt an, wie gut er in der Lage ist, das zu messen, was er zu messen vorgibt (z.B. Intelligenz, Motivation, Persönlichkeitsmerkmale). „Inhaltliche Validität“ oder „Augenscheinvalidität“ besitzt ein Test dann, wenn es aufgrund der Art der Testung (Fragen, Leistungen usw.) offensichtlich ist, welcher Aspekt sich im Testergebnis hauptsächlich niederschlägt (z.B. Additionstest für Rechenfertigkeit, Bildermerktest für Vorstellungsfähigkeit). Die empirische Validitätsprüfung eines Tests geschieht hauptsächlich durch Berechnung des statistischen Zusammenhanges (Korrelation) seiner Werte mit einem plausiblen Kennwert („Kriteriumsvalidität“) oder mit einem anderen Test, der den gleichen Aspekt zu messen vorgibt („Konstruktvalidität“). Beispielsweise könnte bei Schülerinnen und Schülern für einen Test über rechnerische Intelligenz die Mathematiknote als Validitätskriterium oder ein ebenfalls auf Rechenleistungen bezogener anderer Test als Validitätskonstrukt herangezogen werden.
Merksatz
Ein Test ist ein wissenschaftlich begründetes, normiertes und bestimmten Gütekriterien unterworfenes Verfahren mit dem Ziel einer quantitativen Erfassung von Merkmalen.
Zwischen den genannten drei Gütekriterien besteht allerdings eine Implikationsbeziehung: Wenn ein Test nicht objektiv ist, kann er nicht reliabel sein, und wenn er nicht reliabel ist, ist er nicht valide. Wenn nämlich bereits die Datenerhebung stark fehlerbehaftet ist, können bei wiederholten Messungen keine gleichen Resultate auftreten, und wenn Letzteres nicht gesichert ist, kann auch die zu messende empirische Eigenschaft nicht befriedigend von anderen Eigenschaften unterschieden werden.
Insbesondere bei der Konstruktion von Tests werden neben Objektivität, Reliabilität und Validität noch weitere, ebenfalls wichtige Gütekriterien überprüft (s. Kubinger, 2003): Skalierung (quantitative Interpretierbarkeit der Testwerte), Normierung (Vergleichsmöglichkeit mit Bevölkerungsgruppen), Fairness (Chancengleichheit für alle Bevölkerungsgruppen), Ökonomie (Minimum an Ressourcenverbrauch), Zumutbarkeit (Minimum an zeitlicher, emotionaler und psychischer Belastung der Probandinnen und Probanden) und Unverfälschbarkeit (geringe Möglichkeit zur willkürlichen Beeinflussung der Testergebnisse durch die Testpersonen).
| Tab 3.1

Das Polaritätsprofil ist eine in der Psychologie sehr verbreitete Methode zur Erfassung einstellungsbezogener oder gefühlsmäßiger Reaktionen auf Objekte, Personen oder Situationen. Dabei wird von den Versuchspersonen eine Reihe von Eigenschaften oder Eigenschaftspaaren (ca. 5–25) hinsichtlich ihres Zutreffens zahlenmäßig eingestuft.
In der Philosophie den Tests sehr ähnlich und ebenfalls sehr verbreitet sind Ratingverfahren, mittels derer Eigenschaften von Personen, Objekten oder Situationen (z.B. Wahrnehmungen, Ausdruckswirkungen oder Einstellungsintensitäten) anhand von Zahlenzuordnungen quantitativ eingestuft werden. Ein Beispiel dafür ist das Polaritätsprofil („Semantisches Differential“; Tab. 3.1). In anderen Ratings bzw. Skalierungen wird etwa der Grad an Zustimmung zu Meinungen in Prozentpunkten, die Bewertung von Objekten oder Aspekten in Schulnoten oder eine Präferenzentscheidung mittels Punktesystem angegeben.
3.7.5 |BeobachtungDie Selbst- und Fremdbeobachtung zählt zu den ältesten Forschungsinstrumenten der Psychologie. Die wissenschaftliche Beobachtung unterscheidet sich von jener des Alltags durch ihre Theoriegeleitetheit und Systematik. „Unter Beobachtung versteht man das systematische Erfassen von wahrnehmbaren Verhaltensweisen, Handlungen oder Interaktionen einer Person oder Personengruppe zum Zeitpunkt ihres Auftretens“ (Ebster & Stalzer, 2003, 221). Grundsätzlich sollte die Beobachtung als Mittel der Informationsgewinnung in allen Untersuchungen zumindest begleitend eingesetzt werden, und auch die beschriebenen Gütekriterien von Tests sollten eigentlich für alle Datengewinnungsverfahren in der Psychologie gelten. So sind auch Beobachtungen einer Objektivitätsprüfung zu unterziehen, indem die Übereinstimmung verschiedener, unabhängiger Beobachterinnen oder Beobachter festgestellt wird.