



- -
- 100%
- +
Entre 1780 y 1820, casi al mismo tiempo que Laplace y Gauss estaban haciendo sus contribuciones al aprendizaje estadístico, un ingeniero escocés llamado William Playfair estaba inventando gráficos estadísticos y sentando las bases para la visualización de datos y el análisis exploratorio de datos modernos. Playfair inventó el gráfico de líneas y el gráfico de área para datos de series temporales, el gráfico de barras para ilustrar comparaciones entre cantidades de diferentes categorías y el gráfico circular para ilustrar proporciones dentro de un conjunto. La ventaja de visualizar datos cuantitativos es que nos permite usar nuestras poderosas habilidades visuales para resumir, comparar e interpretar datos. Es cierto que es difícil visualizar conjuntos de datos grandes (muchos puntos de datos) o complejos (muchos atributos), pero la visualización de datos sigue siendo una parte importante de la ciencia de datos. En particular, es útil para ayudar a los científicos de datos a explorar y comprender los datos con los que están trabajando. Las visualizaciones también pueden ser útiles para comunicar los resultados de un proyecto de ciencia de datos. Desde la época de Playfair, la variedad de gráficos de visualización de datos ha crecido constantemente, y hoy en día hay investigaciones en curso sobre el desarrollo de enfoques novedosos para visualizar grandes conjuntos de datos multidimensionales. Un desarrollo reciente es el algoritmo de incrustación de vecino estocástico distribuido en t (t-SNE), que es una técnica útil para reducir datos de alta dimensión a dos o tres dimensiones, lo que facilita la visualización de esos datos.
Los desarrollos en la teoría de la probabilidad y las estadísticas continuaron hasta el siglo XX. Karl Pearson desarrolló pruebas de hipótesis modernas, y R. A. Fisher desarrolló métodos estadísticos para el análisis multivariado e introdujo la idea de la estimación de máxima verosimilitud en la inferencia estadística como un método para sacar conclusiones basadas en la probabilidad relativa de eventos. El trabajo de Alan Turing en la Segunda Guerra Mundial condujo a la invención de la computadora electrónica, que tuvo un impacto dramático en las estadísticas porque permitió cálculos estadísticos mucho más complejos. A lo largo de la década de 1940 y las décadas posteriores, se desarrollaron varios modelos computacionales importantes que todavía se usan ampliamente en la ciencia de datos. En 1943, Warren McCulloch y Walter Pitts propusieron el primer modelo matemático de una red neuronal. En 1948, Claude Shannon publicó “Una teoría matemática de la comunicación” y al hacerlo fundó la teoría de la información. En 1951, Evelyn Fix y Joseph Hodges propusieron un modelo para el análisis discriminatorio (lo que ahora se llamaría un problema de clasificación o reconocimiento de patrones) que se convirtió en la base de los modelos de vecinos más cercanos modernos. Estos desarrollos posguerra culminaron en 1956 con el establecimiento del campo de la inteligencia artificial en un taller en Dartmouth College. Incluso en esta etapa temprana del desarrollo de la inteligencia artificial, el término aprendizaje automático estaba comenzando a usarse para describir programas que le daban a una computadora la capacidad de aprender de los datos. A mediados de la década de 1960, se hicieron tres contribuciones importantes al aprendizaje automático. En 1965, el libro de Nils Nilsson titulado Learning Machines mostró cómo las redes neuronales podían usarse para aprender modelos lineales para clasificar. Al año siguiente, Earl B. Hunt, Janet Marin y Philip J. Stone desarrollaron el marco del sistema de aprendizaje de conceptos, que fue el progenitor de una importante familia de algoritmos del aprendizaje automático que indujeron modelos de árbol de decisión a partir de datos según un modelo descedente. Casi al mismo tiempo, varios investigadores independientes desarrollaron y publicaron versiones tempranas del algoritmo de agrupamiento k-means, ahora el algoritmo estándar utilizado para la segmentación de (clientes) datos.
El campo del aprendizaje automático está en el núcleo de la ciencia de datos moderna porque proporciona algoritmos que pueden analizar automáticamente grandes conjuntos de datos para extraer patrones potencialmente interesantes y útiles. El aprendizaje automático ha seguido desarrollándose e innovando hasta el día de hoy. Algunos de los desarrollos más importantes incluyen modelos de conjunto, donde las predicciones se realizan utilizando un conjunto (o comité) de modelos, con cada modelo votando en cada consulta, y redes neuronales de aprendizaje profundo, que tienen múltiples (es decir, más de tres) capas de neuronas. Estas capas más profundas de la red pueden descubrir y aprender representaciones de atributos complejos (compuestos de múltiples atributos de entrada interactivos que han sido procesados por capas anteriores), que a su vez permiten a la red aprender patrones que se generalizan a través de los datos de entrada. Debido a su capacidad para aprender atributos complejos, las redes de aprendizaje profundo son particularmente adecuadas para datos de alta dimensión y, por lo tanto, han revolucionado una serie de campos, incluida la visión artificial y el procesamiento del lenguaje natural.
Como discutimos en nuestra revisión de la historia de la base de datos, los primeros años de la década de 1970 marcaron el comienzo de la tecnología de base de datos moderna con el modelo de datos relacionales de Edgar F. Codd y la posterior explosión de la generación y el almacenamiento de datos que condujeron al desarrollo del almacenamiento de datos en la década de 1990 y más recientemente al fenómeno del big data. Sin embargo, mucho antes de la aparición del big data, a fines de los años ochenta y principios de los noventa, era evidente la necesidad de un campo de investigación dirigido específicamente al análisis de estos grandes conjuntos de datos. Fue alrededor de esta época que el término minería de datos comenzó a usarse en las comunidades de bases de datos. Como ya hemos discutido, una respuesta a esta necesidad fue el desarrollo de almacenes de datos. Sin embargo, otros investigadores de bases de datos respondieron contactándose con otros campos de investigación, y en 1989 Gregory Piatetsky-Shapiro organizó el primer taller sobre descubrimiento de conocimiento en bases de datos (KDD). El anuncio del primer taller de KDD resume claramente cómo el taller se centró en un enfoque multidisciplinario para el problema del análisis de grandes bases de datos.
El descubrimiento de conocimiento en bases de datos plantea muchos problemas interesantes, especialmente cuando las bases de datos son grandes. Dichas bases de datos suelen ir acompañadas de un conocimiento sustancial del dominio que puede facilitar significativamente el descubrimiento. El acceso a grandes bases de datos es costoso, de ahí la necesidad de muestreo y otros métodos estadísticos. Finalmente, el descubrimiento de conocimiento en bases de datos puede beneficiarse de muchas herramientas y técnicas disponibles de varios campos diferentes, incluidos sistemas expertos, aprendizaje automático, bases de datos inteligentes, adquisición de conocimiento y estadísticas.1
De hecho, los términos descubrimiento de conocimiento en bases de datos y minería de datos describen el mismo concepto, la distinción es que la minería de datos es más frecuente en las comunidades empresariales y el KDD es más frecuente en las comunidades académicas. Hoy en día, estos términos se usan indistintamente,2 y muchos de los principales lugares académicos usan ambos. De hecho, la principal conferencia académica en este campo es la Conferencia Internacional sobre Descubrimiento de Conocimiento y Minería de Datos.
El surgimiento y la evolución de la ciencia de datos
El término ciencia de datos adquirió importancia a fines de la década de 1990 en discusiones relacionadas con la necesidad de que los estadísticos se unieran a los científicos informáticos para aportar rigor matemático al análisis computacional de grandes conjuntos de datos. En 1997, la conferencia pública de C. F. Jeff Wu “¿Estadísticas = Ciencia de datos?” destacó una serie de tendencias prometedoras para la estadística, incluida la disponibilidad de conjuntos de datos grandes/complejos en bases de datos masivas y el creciente uso de algoritmos y modelos computacionales. Concluyó la conferencia pidiendo que se cambiara el nombre de las estadísticas a “ciencia de datos”.
En 2001, William S. Cleveland publicó un plan de acción para crear un departamento universitario en el campo de la ciencia de datos (Cleveland 2001). El plan enfatizaba la necesidad de que la ciencia de datos fuera una asociación entre las matemáticas y la informática. También enfatizaba la necesidad de que la ciencia de datos se entiendiera como un esfuerzo multidisciplinario y que los científicos de datos aprendieran cómo trabajar y relacionarse con expertos en la materia. En el mismo año, Leo Breiman publicó “Statistical Modeling: The Two Cultures” (2001). En este documento, Breiman caracteriza el enfoque tradicional de las estadísticas como una cultura de modelado de datos que considera que el objetivo principal del análisis de datos es identificar el modelo de datos estocástico (oculto) (por ejemplo, regresión lineal) que explica cómo se generaron los datos. Contrasta esta cultura con la cultura de modelado algorítmico que se enfoca en usar algoritmos de computadora para crear modelos de predicción que sean precisos (en lugar de explicativos, en términos de cómo se generaron los datos). La distinción de Breiman entre un enfoque estadístico en modelos que explican los datos versus un enfoque algorítmico en modelos que pueden predecir con precisión los datos destaca una diferencia central entre los estadísticos y los investigadores de aprendizaje automático. El debate entre estos enfoques todavía está en curso dentro de las estadísticas (véase, por ejemplo, Shmueli 2010). En general, hoy en día la mayoría de los proyectos de ciencia de datos están más alineados con el enfoque de aprendizaje automático de construir modelos de predicción precisos y menos preocupados por el enfoque estadístico en la explicación de los datos. Entonces, aunque la ciencia de datos se hizo prominente en las discusiones relacionadas con las estadísticas y todavía toma prestados métodos y modelos de las estadísticas, con el tiempo ha desarrollado su propio enfoque distinto para el análisis de datos.
Desde 2001, el concepto de ciencia de datos se ha ampliado mucho más allá de la redefinición de las estadísticas. Por ejemplo, en los últimos 10 años ha habido un enorme crecimiento en la cantidad de datos generados por la actividad en línea (venta minorista en línea, redes sociales y entretenimiento en línea). La recopilación y preparación de estos datos para su uso en proyectos de ciencia de datos ha resultado en la necesidad de que los científicos de datos desarrollen las habilidades de programación y piratería para extraer, fusionar y limpiar datos (a veces no estructurados) de fuentes web externas. Además, la aparición del big data ha significado que los científicos de datos deben poder trabajar con tecnologías del big data, como Hadoop. De hecho, hoy en día el papel de un científico de datos se ha vuelto tan amplio que existe un debate continuo sobre cómo definir la experiencia y las habilidades necesarias para llevar a cabo esta función.3 Sin embargo, es posible enumerar la experiencia y las habilidades que son relevantes para el rol en las que la mayoría de las personas están de acuerdo, que son las que se muestran en la Figura 1. Es difícil para un individuo dominar todas estas áreas y, de hecho, la mayoría de los científicos de datos generalmente tienen un conocimiento profundo y experiencia real en solo un subconjunto de ellos. Sin embargo, es importante comprender y estar al tanto de la contribución de cada área a un proyecto de ciencia de datos.
Los científicos de datos deberían tener cierta experiencia en el dominio. La mayoría de los proyectos de ciencia de datos comienzan con un problema específico del dominio del mundo real y la necesidad de diseñar una solución basada en datos para este problema. Como resultado, es importante que un científico de datos tenga suficiente experiencia en el dominio para comprender el problema, por qué es importante y cómo una solución de ciencia de datos al problema podría encajar en los procesos de una organización. Esta experiencia en el dominio guía al científico de datos mientras trabaja para identificar una solución optimizada.
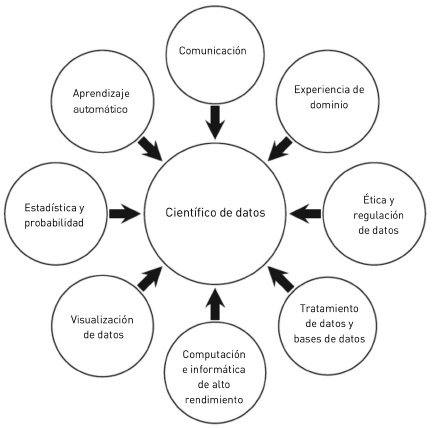
Figura 1. Un desiderátum de conjunto de habilidades para un científico de datos.
También le permite interactuar con expertos en dominios reales de una manera significativa para que pueda ilicitar y comprender el conocimiento relevante sobre el problema subyacente. Además, tener cierta experiencia en el dominio del proyecto le permite al científico de datos aportar sus experiencias al trabajar en proyectos similares en los mismos dominios y otros relacionados para definir el enfoque y el alcance del proyecto.
Los datos están en el centro de todos los proyectos de ciencia de datos. Sin embargo, el hecho de que una organización tenga acceso a los datos no significa que pueda usarlos legal o éticamente. En la mayoría de las jurisdicciones, existe una legislación antidiscriminatoria y de protección de datos personales que regula y controla el uso de la utilización de datos. Como resultado, un científico de datos necesita comprender estas regulaciones y también, en términos más generales, tener una comprensión ética de las implicaciones de su trabajo si quiere usar los datos de manera legal y adecuada. Volveremos a este tema en el capítulo 6, en el que discutimos las regulaciones legales sobre el uso de datos y las cuestiones éticas relacionadas con la ciencia de datos.
En la mayoría de las organizaciones, una parte importante de los datos provendrá de las bases de datos de la organización. Además, a medida que crece la arquitectura de datos de una organización, los proyectos de ciencia de datos comenzarán a incorporar datos de una variedad de otras fuentes de datos, que comúnmente se conocen como “fuentes de big data”. Los datos en estas fuentes de datos pueden existir en una variedad de formatos diferentes, generalmente una base de datos de alguna forma: relacional, NoSQL o Hadoop. Todos los datos en estas diversas bases de datos y fuentes de datos deberán integrarse, limpiarse, transformarse, normalizarse, etc. Estas tareas tienen muchos nombres, como extracción, transformación y carga, organización de datos, tratamiento de datos, fusión de datos, procesamiento de datos, etc. Al igual que los datos de origen, los datos generados a partir de las actividades de ciencia de datos también deben almacenarse y administrarse. Una vez más, una base de datos es la ubicación de almacenamiento típica para los datos generados por estas actividades porque luego se pueden distribuir y compartir fácilmente con diferentes partes de la organización. Como consecuencia, los científicos de datos necesitan tener las habilidades para interactuar y manipular datos en bases de datos.
Una gama de habilidades y herramientas informáticas permite a los científicos de datos trabajar con grandes datos y procesarlos en información nueva y significativa. La informática de alto rendimiento (HPC en inglés) implica agregar potencia informática para ofrecer un rendimiento superior al que se puede obtener de una computadora independiente. Muchos proyectos de ciencia de datos funcionan con un conjunto de datos muy grande y algoritmos de aprendizaje automático que son costosos informáticamente. En estas situaciones, es importante tener las habilidades necesarias para acceder y utilizar los recursos de HPC. Más allá de HPC, ya hemos mencionado la necesidad de que los científicos de datos puedan eliminar, limpiar e integrar datos web, así como manejar y procesar texto e imágenes no estructurados. Además, un científico de datos también puede terminar escribiendo aplicaciones internas para realizar una tarea específica o alterar una aplicación existente para sintonizarla con los datos y el dominio que se está procesando. Finalmente, también se requieren habilidades informáticas para poder comprender y desarrollar los modelos de aprendizaje automático e integrarlos en la producción o aplicaciones analíticas o de fondo en una organización.
La presentación de datos en un formato gráfico hace que sea mucho más fácil ver y comprender lo que sucede con los datos. La visualización de datos se aplica a todas las fases del proceso de ciencia de datos. Cuando los datos se inspeccionan en forma de tabla, es fácil pasar por alto cosas como valores atípicos o tendencias en las distribuciones o cambios sutiles en los datos a través del tiempo. Sin embargo, cuando los datos se presentan en la forma gráfica correcta, estos aspectos de los datos pueden resaltar. La visualización de datos es un campo importante y en crecimiento, y recomendamos dos libros, The Visual Display of Quantitative Information de Edward Tufte (2001) y Show Me the Numbers: Designing Tables and Graphs to Enlighten de Stephen Few (2012) como una excelente introducción a los principios y técnicas de visualización efectiva de datos.
Métodos de estadística y probabilidad se utilizan en todo el proceso de ciencia de datos, desde la recopilación inicial y la investigación de los datos hasta la comparación de los resultados de diferentes modelos y análisis producidos durante el proyecto. El aprendizaje automático implica el uso de una variedad de técnicas avanzadas de estadística e informática para procesar datos para encontrar patrones. El científico de datos que participa en los aspectos aplicados del aprendizaje automático no tiene que escribir sus propias versiones de algoritmos de aprendizaje automático. Al comprender estos algoritmos, para qué se pueden usar, qué significan los resultados que generan y qué tipo de algoritmos de datos particulares se pueden ejecutar, el científico de datos puede considerar los algoritmos de aprendizaje automático como un cuadro gris. Esto le permite concentrarse en los aspectos aplicados de la ciencia de datos y probar los diversos algoritmos para ver cuáles funcionan mejor para el escenario y los datos que le interesan.
Finalmente, un aspecto clave de ser un científico de datos exitoso es poder comunicar la historia en los datos. Esta historia podría descubrir el conocimiento que ha revelado el análisis de los datos o cómo los modelos creados durante un proyecto se ajustan a los procesos de una organización y el probable impacto que tendrán en el funcionamiento de la misma. No tiene sentido ejecutar un proyecto brillante de ciencia de datos a menos de que se utilicen y comuniquen los resultados de este de tal manera que los colegas con antecedentes no técnicos puedan comprenderlos y confiar en ellos.
¿Dónde se usa la ciencia de datos?
La ciencia de datos impulsa la toma de decisiones en casi todos los aspectos de las sociedades modernas. En esta sección, describimos tres estudios de caso que ilustran el impacto de la ciencia de datos: las compañías de consumo que usan la ciencia de datos para ventas y marketing; los gobiernos que utilizan la ciencia de datos para mejorar la salud, la justicia penal y la planificación urbana; y las franquicias deportivas profesionales que utilizan ciencia de datos en el reclutamiento de jugadores.
Ciencia de datos en ventas y marketing
Walmart tiene acceso a grandes conjuntos de datos sobre las preferencias de sus clientes mediante el uso de sistemas de punto de venta, rastreando el comportamiento del cliente en el sitio web de Walmart y los comentarios de las redes sociales sobre Walmart y sus productos. Durante más de una década, Walmart ha estado utilizando la ciencia de datos para optimizar los niveles de stock en las tiendas, un ejemplo bien conocido es cuando en 2004 reabasteció con Pop-Tarts de fresas sus tiendas en la ruta del huracán Francis en base a un análisis de datos de ventas previos al huracán Charley, que había golpeado unas semanas antes. Más recientemente, Walmart ha utilizado la ciencia de datos para impulsar sus ingresos minoristas en términos de introducir nuevos productos basados en el análisis de las tendencias de las redes sociales, el análisis de la actividad de las tarjetas de crédito para hacer recomendaciones de productos a los clientes y la optimización y personalización de la experiencia en línea de los clientes en el sitio web de Walmart. Walmart atribuye un aumento del 10% al 15% en las ventas en línea a las optimizaciones de ciencia de datos (DeZyre 2015).
El equivalente de ventas superiores y ventas cruzadas en el mundo en línea es el “sistema de recomendación”. Si has visto una película en Netflix o has comprado un artículo en Amazon, sabrás que estos sitios web utilizan los datos que recopilan para proporcionar sugerencias sobre lo que debes ver o comprar a continuación. Estos sistemas de recomendación se pueden diseñar para guiarte de diferentes maneras: algunos te guían hacia éxitos de taquilla y bestsellers, mientras que otros te guían hacia artículos de nicho que son específicos para tus gustos. El libro de Chris Anderson, La Economía Long Tail (2008), argumenta que a medida que la producción y la distribución se vuelven menos costosas, los mercados pasan de vender grandes cantidades de un pequeño número de artículos exitosos a vender cantidades más pequeñas de un mayor número de artículos de nicho. Esta compensación entre impulsar las ventas de productos exitosos o de nicho es una decisión de diseño fundamental para un sistema de recomendación y afecta los algoritmos de ciencia de datos utilizados para implementar estos sistemas.
Gobiernos que usan ciencia de datos
En los últimos años, los gobiernos han reconocido las ventajas de adoptar la ciencia de datos. En 2015, por ejemplo, el gobierno de Estados Unidos nombró al Dr. D. J. Patil como el primer científico de datos en jefe. Algunas de las mayores iniciativas de ciencia de datos encabezadas por el gobierno de Estados Unidos han estado en salud. La ciencia de datos está en el centro de las iniciativas “Cancer Moonshot”4 y “Precision Medicine”. La iniciativa “Precision Medicine” [Medicina de precisión] combina la secuenciación del genoma humano y la ciencia de datos para diseñar medicamentos para pacientes individuales. Una parte de la iniciativa es el programa “All of Us” [Todos nosotros], 5 que recopila datos ambientales, de estilo de vida y biológicos de más de un millón de voluntarios para crear los conjuntos de datos más grandes del mundo para la medicina de precisión. La ciencia de datos también está revolucionando la forma en que organizamos nuestras ciudades: se utiliza para rastrear, analizar y controlar los sistemas ambientales, de energía y de transporte e informar la planificación urbana a largo plazo (Kitchin 2014a). Volveremos al tema de la salud y las ciudades inteligentes en el capítulo 7, en el que discutiremos cómo la ciencia de datos será aún más importante en nuestras vidas en las próximas décadas.
La iniciativa de datos policiales del gobierno de EE.UU.6 se centra en el uso de la ciencia de datos para ayudar a los departamentos de policía a comprender las necesidades de sus comunidades. La ciencia de datos también se está utilizando para predecir los puntos críticos del crimen y la reincidencia. Sin embargo, los grupos de libertad civil han criticado algunos de los usos de la ciencia de datos en la justicia penal. En el capítulo 6, discutiremos las preguntas de privacidad y ética planteadas por la ciencia de datos, y uno de los factores interesantes en esta discusión es que las opiniones que las personas tienen en relación con la privacidad personal y la ciencia de datos varían de un dominio a otro. Muchas personas que están contentas de que sus datos personales sean utilizados para investigaciones médicas financiadas con fondos públicos tienen opiniones muy diferentes cuando se trata del uso de datos personales para la vigilancia y la justicia penal. En el capítulo 6, también discutiremos el uso de datos personales y ciencia de datos para determinar las primas de seguros de vida, salud, automóvil, hogar y viajes.
Ciencia de datos en deportes profesionales
La película Moneyball (Bennett Miller 2011), protagonizada por Brad Pitt, muestra el creciente uso de la ciencia de datos en los deportes modernos. La película se basa en el libro del mismo título (Lewis 2004), que cuenta la verdadera historia de cómo el equipo de béisbol Oakland Athletics utilizó la ciencia de datos para mejorar su reclutamiento de jugadores. La gerencia del equipo identificó que las estadísticas de porcentaje en base y el poder de un bateador eran indicadores más informativos del éxito ofensivo que las estadísticas tradicionalmente enfatizadas en el béisbol, como el promedio de bateo de un jugador. Esta idea permitió a Oakland Athletics reclutar una lista de jugadores infravalorados y tener un desempeño por encima de su presupuesto. El éxito de Oakland Athletics con la ciencia de datos ha revolucionado el béisbol, y la mayoría de los otros equipos de béisbol ahora integran estrategias similares basadas en datos en sus procesos de reclutamiento.